I am convinced that we're entering an exciting new era of traditional SAST tools + LLMs which will obsolete pretty much all the existing tools on the market (including our tool, Semgrep).
This is a major change to my belief system in 2023. Back then, I believed that AI systems would dominate remediation guidance (explain why and how to fix this vulnerability) but I was skeptical of going beyond that. This wasn't a controversial belief, and indeed a lot of vendors (Semgrep, Snyk, and Github for instance) have been using AI to do exactly that.
What changed for me in 2024 was realizing that LLMs could change the game in the context of the findings engine itself. Even with great remediation, you're limited by the signal-to-noise ratio (SNR) of the scanner. Here's my napkin formula:

So concretely, what's the value of customization? Finding SNR. Finding SNR needs to be ≥70-90% because of human cognitive biases: above 10-30% false positives engineers tune out:, even a true positive preceded by a false positive will lead to a cascading perception of false positives. So an AppSec scanner can definitely have negative value (!) below a certain SNR. See napkin sketch:

If you start with only custom rules, you can easily achieve >90% SNR for developers – because you manually vetted what you're going to find. Look for examples where we call this super-user function without invoking our authentication API beforehand – is so org-specific that no vendor will ship it out of the box, but is extremely high-signal if it fires.
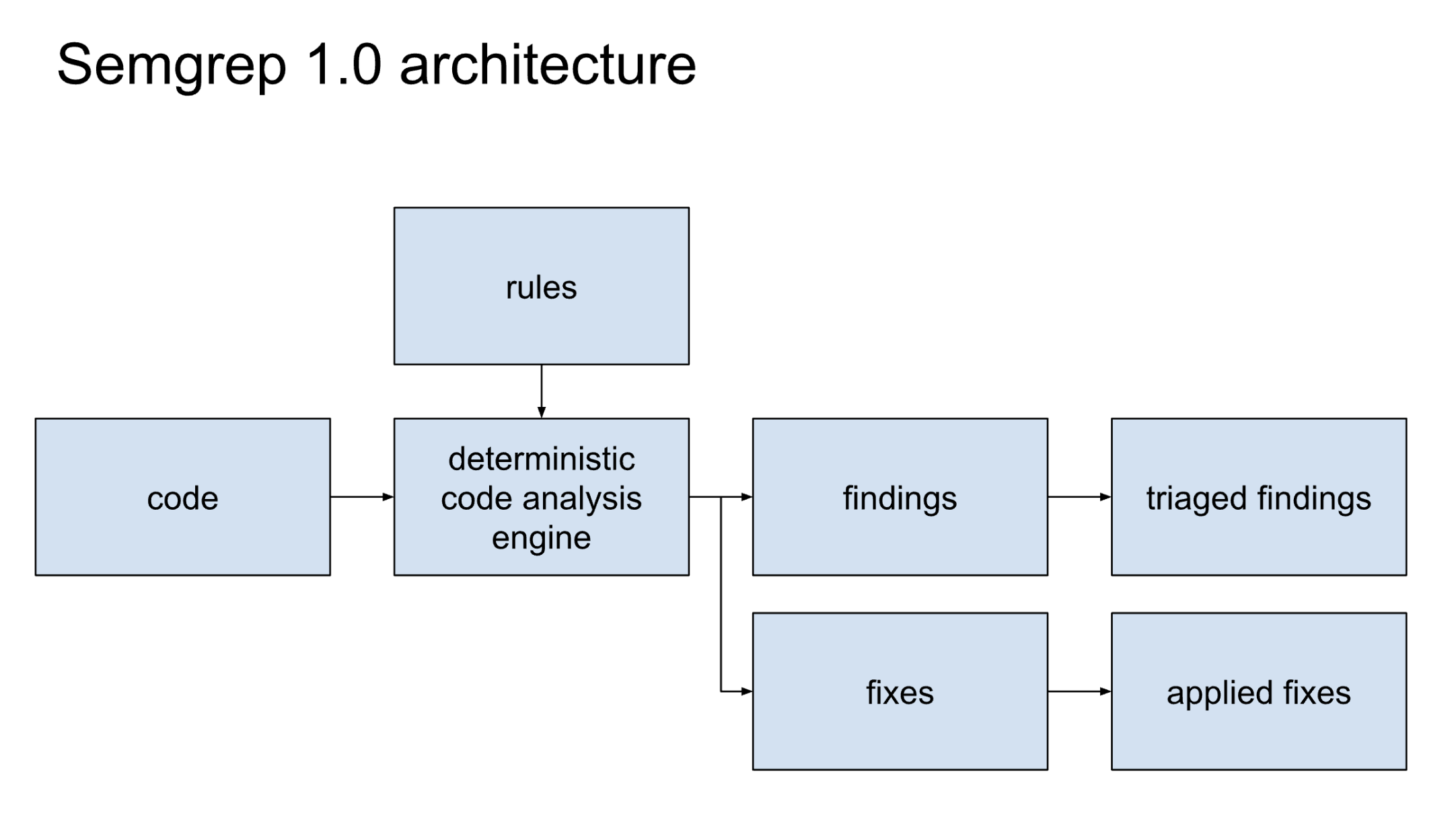
This value prop accounts for the early product-market fit of Semgrep 1.0.
What changes with LLMs?
At the start of the year my co-founder Drew moved full time into focusing on the question of "what would it look like to disrupt Semgrep with LLMs? If we threw away all our prior work, what would we build?"
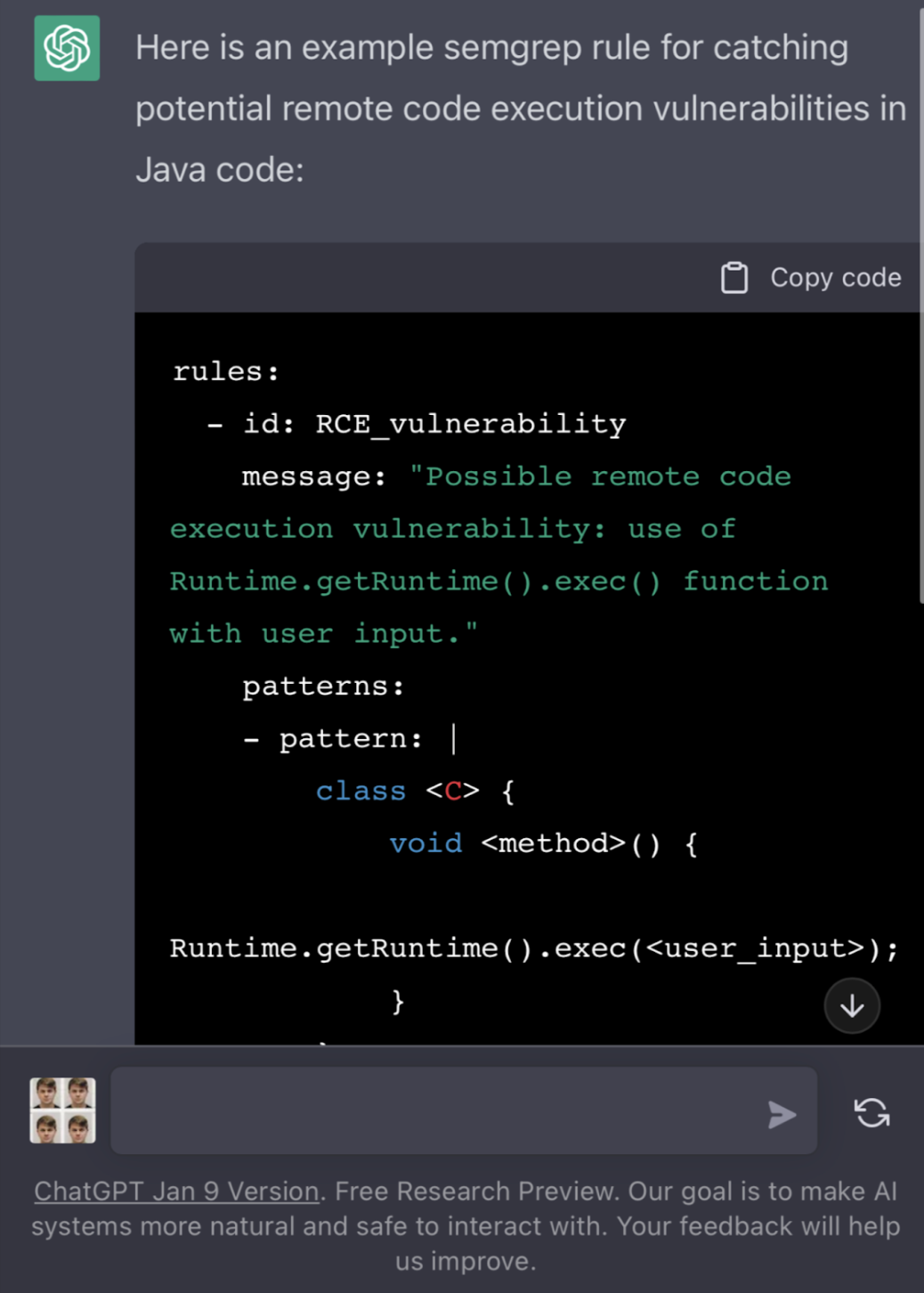
An advantage of Semgrep's open-source nature is that we can already use LLMs to write semgrep rules: users started doing this with the first release of ChatGPT.
But just asking ChatGPT to write a rule still requires a lot of domain-specific knowledge. We've tried to make it easier and easier to write Semgrep rules.
A breakthrough: Memories!
Initial AI application involved adding "LLM suggested fixes" where we brought code context (not just the SARIF output, but extra dataflow & trace information from the deterministic engine) into the LLM and asked it to suggest a fix (blue arrow). Some players (us included) also started using AI a lot to write generic rules that would ship with the paid product (Semgrep Pro rules & engine).
But the real breakthrough was getting the Memories feature to work well: when a user triages a finding or applies a fix, we not only apply that to all previous findings, but also to the rules themselves:
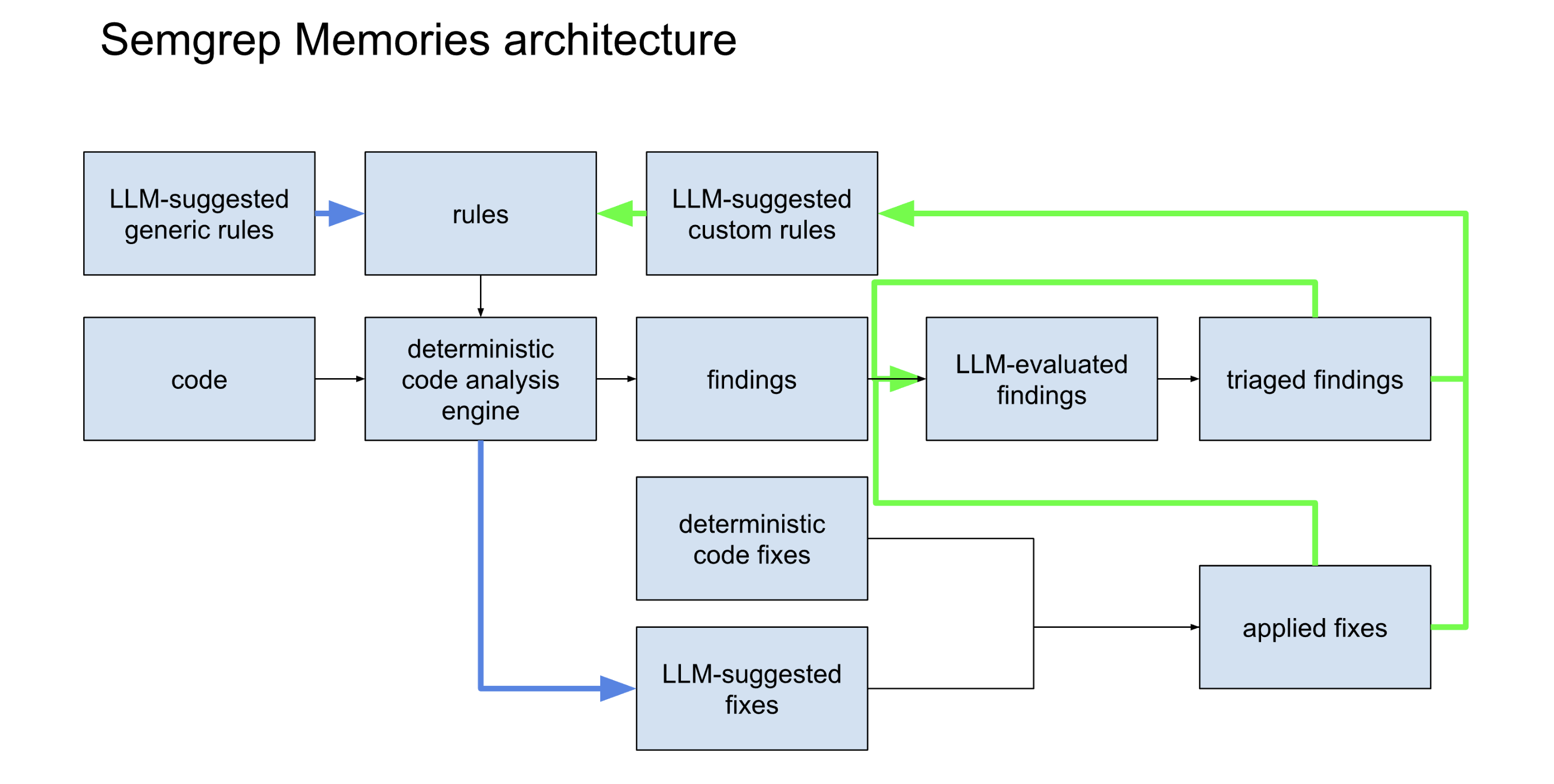
Now everyone can customize – no YAML required! Context wraps the engine. The very act of triaging is customization.
Does it work?
The memories architecture isn't exactly surprising. But the devil is in the details of making it actually work in the hands of users. Our private beta yielded encouraging results. Here are a few examples (anonymized):
While triaging, one private beta user found that a large number of the server-side request forgery (SSRF) findings that Semgrep identified, while valid pattern matches, were actually mitigated by context about their internal services that SAST tools would never have (without custom rule writing).
The customer added two memories, similar to the following:

When a new memory is added, Semgrep Assistant re-analyzes similar findings in the backlog. After adding these two memories, the customer was able to close 47% of their SSRF backlog findings (nearly 50 findings) with the help of AI.
Another user added a basic memory about cookie attributes, and was immediately able to close 62 findings in their backlog:

Conclusion
Security experts will always be essential, but I see a future where the need for "security tool experts" may diminish. By leveraging LLMs to encode security-relevant, organization-specific contexts into Semgrep's deterministic SAST engine, any practitioner will have access to a scanner that "understands" the security-relevant nuances of their codebase without any manual customization or tool-specific expertise.
While Semgrep rules are unique in that they look like source code and are easy to write (that’s what makes the Semgrep / LLM synergy possible in the first place!), it’s easy for us to see that the future lies in the practitioner not dealing with any YAML or regex wrestling at all.
By combining static analysis and LLMs, we’ll be able to add semi-autonomous capabilities to our platform that give security teams and developers a significant and measurable chunk of time back every day - but in a manner that preserves the determinism and reproducibility important in security concepts.
Two of these features, noise filtering and V1 of memories, have launched today and you can read more about them here!




.jpg)
