Can LLMs Detect IDORs? Understanding the Boundaries of AI Reasoning
Analyzing accuracy of LLM generated IDOR findings
Vasilii Ermilov
November 3rd, 2025
TL;DR: We continue our previous research in evaluating Claude Code and OpenAI Codex on finding vulnerabilities in real, open-source applications, with simple prompts and no scaffolding. In this post we dive into the IDOR results, examining when they perform well, and where they struggle.
In total, the models found 15 real, previously unknown vulnerabilities, as well as 93 false positives.
Claude code with Sonnet 4 performed the best.
We break the findings down into four categories, in increasing analysis complexity required:
1) No authorization is being performed at all.
2) All protections are in a small scope (single function or file)
3) There’s custom RBAC logic and/or the permission check is spread across files.
4) Authorization logic is implemented in the middleware, framework, or elsewhere that gets called automatically / implicitly.
In our experiment, we find the coding agents have highest accuracy in the simpler cases (categories 1 and 2), and do not as effectively reason about authorization logic across multiple files (3) or when authorization is applied implicitly by middleware or the framework (4). See the table towards the bottom for the specific breakdown.
We believe prompt engineering and additional scaffolding could improve results in all categories, which we plan to explore in future work.
That experiment used a fairly generic, scripted prompt for all vulnerability types, asking the AI to:
I am a core developer of this app. It's been reported to me that there are several IDOR vulnerabilities in the code base. I need your expertise to find all of them!
# Instructions
- Find all {IDOR vulnerabilities in my code, don't worry about third-party code.
- Explain why they are real security vulnerabilities I should care about; give code snippets from the code to support your analysis (trace from entry points); maybe some clue on how to trigger the issue for testing.
- Report all IDOR vulnerabilities using the SARIF JSON format that you will write within the <SARIF_OUTPUT>...</SARIF_OUTPUT> tag; make sure it's valid JSON.
- Fix these security issues in the code.
Don't ask for confirmation, just do it.
While this prompt gave us a lower bound, the results require us to follow-up. This post zooms in on IDOR. We are moving from "Can AI find IDORs?" to "Why does AI succeed or fail at finding IDORs, and can we make it better?"
To do this, we re-frame our original research questions with a specific focus on this critical vulnerability class:
What makes IDOR different? Unlike taint-flow issues like SQL injection, IDOR is often a flaw in business logic. How well can an LLM reason about missing security controls (e.g., "this function should check the user ID but doesn't") versus other common vulnerabilities?
What are the common reasons for the high FP rate for IDORs? In our first study, 78% of Claude's IDOR findings were false positives. What patterns (e.g., misunderstood business logic, lack of authorization context, specific ordering of call sequences or patterns in code) do these incorrect findings share?
How deterministic is IDOR detection? Our original post noted high non-determinism. If we run the exact same IDOR prompt multiple times, how much do the findings vary?
In this post, we're getting much more precise. We will analyze the findings from the original study and explore how useful LLMs can be at identifying IDORs.
Understanding IDOR
Insecure Direct Object Reference (IDOR) is a vulnerability class that occurs when a web application exposes internal object identifiers such as user IDs, filenames, or database keys in URLs or HTTP request parameters without proper access control. As the endpoint is missing accessing control, by manipulating these identifiers, attackers can gain unauthorized access to or modify data by simply changing the identifier.
These issues are notoriously common, often subtle, and remain a persistent challenge for both manual and automated testing approaches, as detecting them requires a deep understanding of the web application’s logic and how its HTTP parameters relate to user access. For more details about how this vulnerability works you can refer to our reference articles.
We’ve chosen this vulnerability class because it’s both high-impact and remarkably prevalent in modern web applications. IDORs remain one of the most common findings among bug bounty hunters (#4 in HackerOne top vulnerability types list). They can lead to large-scale data breaches, unauthorized access to sensitive information, financial losses, and severe reputational damage for organizations. For practical illustrations of the potential impact of such a bug, consider these HackerOne reports:
@app.route('/user/<int:user_id›')
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user.to_dict())
This simple Flask controller takes a user_id from the route, fetches the user object from the database, and returns it in the response. Now imagine that the user object contains sensitive information:
User object has PII data like home_address , phone_number , passport_number
In this case, any authenticated user could change the user_id in the request and retrieve personally identifiable information (PII) of other users, which is textbook IDOR.
But which part of the code is actually vulnerable? On line 3, the application fetches data from the database, which is a routine operation. On line 4, it returns that data. There’s nothing that would stand out to a static analysis tool.
This time, the controller only returns username and email fields, and let’s assume this information is meant to be publicly visible. In this case, there’s no IDOR, even though the logic looks almost identical.
The only real difference is that sensitive fields were removed from the output. Unfortunately, distinguishing between safe and unsafe code like this isn’t straightforward. It requires understanding more than just the syntax. To truly reason about this, we’d need to know:
Which fields are considered sensitive.
Whether user data is intended to be publicly accessible at all.
Identifying IDORs requires understanding the context of the web application, not just its code. Looking at a more complex example:
The Flask controller returns an invoice belonging to an organization, however there is no verification that the invoice actually belongs to the given organization. This means a user could manipulate the request values organization_id or invoice_id and retrieve invoices from other organizations leading to IDOR.
@app.route('/organization/<int:organization_id›/invoice/<int:invoice_id>')
def get_organization_invoice(organization_id, invoice_id):
organization = Organization.query get_or_404(organization_id)
invoice = Invoice.query.get_or_404(invoice_id)
# Verify that the invoice belongs to the organization
if invoice.organization_id != organization_id:
return jsonify({'error': 'Invoice does not belong to this organization'}), 404
return jsonify({
'invoice': invoice.to_dict(),
'organization_name': organization. name
})
Sometimes code can look correct, e.g. a check was added to ensure that the invoice belongs to a specified organization. However, the code still fails to verify whether the current user belongs to the organization tied to the invoice. As a result, an attacker could still access invoices persisting the vulnerability.
@app.route('/organization/<int:organization_id›/invoice/<int:invoice_id>')
def get_organization_invoice(organization_id, invoice_id):
current_user = get_current_user()
organization = Organization.query get_or_404(organization_id)
invoice = Invoice.query.get_or_404(invoice_id)
# Verify that the user belongs to the organization
if organization not in current_user.organizations:
return jsonify({'error': 'User does not belong to this organization'}), 403
# Verify that the invoice belongs to the organization
if invoice.organization_id != organization_id:
return jsonify({'error': 'Invoice does not belong to this organization'}), 404
return jsonify({
'invoice': invoice.to_dict(),
'organization_name': organization. name
})
This version validates both the relationship between the invoice and the organization, and the user’s membership within that organization. At this point, the endpoint is safe from basic IDORs.
Applications can quickly get even more complex if they support Role-Based Access Control (RBAC), if only users with the “owner” role should have permission to view certain invoices. Missing or misconfigured RBAC logic can easily reintroduce authorization flaws.
To reason effectively about IDOR vulnerabilities in code, we need to know whether:
User input is used to retrieve internal objects.
Objects contain private or sensitive information.
Access to those objects are properly verified.
Role-based access control (RBAC) is correctly implemented for that context.
Static analysis tools can often handle the first point, detecting where user input flows into data access. But understanding the rest requires reasoning about application logic and intent.
This is where large language models (LLMs) could help bridge the gap, by analyzing not just syntax, but semantics, and by inferring context about data sensitivity and access rules that traditional tools miss.
Looking at the Data: Performance and Insights
For some of the LLMs that we used, IDOR bugs achieved the highest true positive (TP) rate among all the vulnerability types we tested. In other words, while IDOR stands out in relative terms, the absolute numbers still indicate a significant amount of noise.
True Positives
False Positives
True Positive Rate
Anthropic Claude Code (v1.0.32, Sonnet 4)
13
46
22% (13/59)
OpenAI Codex (v0.2.0, o4-mini/high reasoning)
0
5
0% (0/5)
OpenAI Codex GPT-5-Codex
2
42
4.5% (2/44)
As the data in the table demonstrates, there is variance in the accuracy of different models in the identification of real vulnerabilities. Surprisingly, discrepancies also existed in the repeatability of reproducing findings. Running the same prompt would produce inconsistent results with only partial overlaps between runs.
The overall impression after manually triaging more than 100 potential IDOR reports discovered:
Code fragments flagged by coding agents looked like legitimate findings. There were no obvious hallucinations or completely nonsensical reports.
LLM’s reasoning was typically limited to a very narrow scope: either a single function or, at best, a single file.
Even if promising on the surface, the vast majority of reported IDORs were incorrect.
Source code that uses annotations or decorators such as @require_role in Flask give clues that an LLM can pick up on when distinguishing a vulnerable condition.
@require_role() annotation is used to control that users have permission to access different routes of the web application
When authentication logic was implemented across multiple files within a project, the LLM inter-file analysis would make an incorrect conclusion about the implementation of access control policies. For example, the design pattern where a separate configuration file is used to inject middleware authorization layers is common in many frameworks. The Django CMS configuration is an example of this and where traditional manual code reviews find challenging in identifying IDOR flaws.
This is a typical Django CMS configuration, the routes are configured in the urls.py file and have custom middleware functions that check access permissions.
Another recurring challenge was that LLMs lacked the ability to assess the real-world severity or intent behind certain patterns. In many cases, url parameters could indeed be manipulated to access additional data, but the data was intentionally public (e.g., public profiles or shared resources). Without context about the application’s intended behaviour, LLMs frequently flagged these cases as vulnerabilities, even though they weren’t actually security issues. If the LLM made an automatic fix to this type of false positive, it could cause regressions that break intended functionality.
Case Studies in IDOR Detection
After triaging ~100 IDOR candidates, we identified a few recurring categories based on how the source code was structured:
1. No verification / protection of the manipulated object at all
In some cases, access control simply wasn’t implemented. When that happens, the only open question is whether the omission was intentional. We even found an app that was supposed to validate project access but hadn’t implemented the check yet.
Here is a simplified version of that code:
from fastapi import APIRouter, Depends
# ...
def validate_project_access(project: str):
#TODO: lets implement it in the next version :)
pass
def list_documents():
"""Return all documents for the given project."""
return {"documents": ["doc1.pdf", "doc2.pdf"]}
project_api = APIRouter(prefix="/{project}", dependencies=[Depends(validate_project_access)])
project_api.include_router(
list_documents,
prefix="/documents",
tags=["documents"]
)
This example is from a FastAPI app: as you can see, the validate_project_access dependency on lines 3–5 is a no-op. The LLM correctly flagged this as a likely authorization gap.
2. All protections reside within a small scope (function / file)
Sometimes all the authorization and business logic relevant to an access decision is contained within a single function or file. In those cases the model has enough local context to reason accurately about whether a route is protected, and LLMs performed well on these patterns in our tests. One real finding of this type that led to a disclosed issue is CVE-2025-59034. It was identified by Claude Code and submitted by our team to the maintainers of the application.
Vulnerable source code:
@HTPAPIHook.register
class UserInfoHook(HTTPAPIHook):
TYPES = ('user',)
RE = r'(?P<user_id>[\d]+)'
VALID_FORMATS = ('json', 'jsonp', 'xml')
def _getParams (self ):
super()._getParams()
self._user_id = self._pathParams['user_id'] l
def export_user (self, user):
from indico.modules.users.schemas import UserSchema
if not user:
raise HTTPAPIError('You need to be logged in', 403)
user = User.get(self._user_id, is_deleted=False)
if not user:
raise HITPAPIError ('Requested user not found', 404)
if not user.can_be_modified(user):
raise HITPAPIError('You do not have access to that info', 403)
return [UserSchema().dump(user)]
user.can_be_modified(user) always returns True
The permission check is implemented incorrectly which allows any user to view account information of any other users. The bug resides within one function which allows the model to successfully detect it. This is a real, exploitable bug, and it highlights one of the key strengths of LLMs: their ability to reason about small, well-defined contexts.
While SAST tools could also identify this type of vulnerability, they typically won’t do so out of the box for custom code that is not relying on a known framework or a library. However, if you’re developing or maintaining an application and want to ensure consistent detection of access control flaws, you can absolutely codify this logic into a deterministic Semgrep rule. Try it for yourself in the Semgrep Playground with an example rule.
3. Custom RBAC logic or the permission check is spread across the app (multiple files and logical layers)
Now, let’s contrast that with a typical false positive scenario, which is something we observed frequently during our analysis:
fetch_project_handler() uses project_id from a user request to retrieve information about the project and return it in the response. No evidence of a permission check in this code snippet.
At first glance, when focusing only on the function itself, it appears that sensitive data could be exposed, leading the model to flag this as a potential IDOR vulnerability. However, once we step back and examine how object permissions are actually enforced within the application, the picture changes:
from flask_login import current_user
# ...
def fetch_project_handler(project_id):
project = db_session.get(Project, project_id)
# ...
if not project.user_has_access(current_user):
raise ForbiddenError("You do not have access to this project")
return {
"id": project.id,
"name": project.name,
"description": project.description
}
Turns out that fetch_project_handler actually checks the ownership when retrieving the Project by its id.
class Project(Base):
__tablename__ = "projects"
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
owner_id = Column(Integer, ForeignKey("users. id"), nullable=False)
owner = relationship("User", back_populates="projects" )
#...
def user_has_access(self, user):
if user is None:
return False
return self.owner_id == user.id
The logic of the ownership check is built into the SQLAlchemy Model class.
Here, we can clearly see that only the owner of the resource is granted access, making the initial finding a false positive. In this case, the model’s narrow reasoning scope caused it to miss the broader security controls in place.
This gap can sometimes be addressed by prompting the LLM to consider additional context. For example, we can explicitly instruct the model to look for authorization mechanisms in the application. And with the right guidance, the model can adjust its reasoning and produce a more accurate conclusion, but usually it will require multiple prompts to be used, however this approach is not protected from hallucinations and false assumptions.
4. Logic implemented in the middleware, framework, or other places that get called automatically (no obvious control flow)
Another complex scenario arises when web frameworks or utility libraries include built-in authorization controls that operate behind the scenes, outside of the explicit control flow visible in the code. A good example of this is the Flask-RESTful library, which extends Flask applications with abstractions for building REST APIs and can also manage authentication and authorization implicitly.
Consider the AdminDashboard controller example:
from flask import jsonify
# ...
class AdminDashboard(AdminAccessControl):
def get(self, project_id):
project_data = self.get_project_data(project_id)
return jsonify(dashboard_data)
At first glance, the controller appears to allow any user to request project data by its ID. However, if we look at the AdminAccessControl class it inherits from, we can see that access control checks, such as login verification and admin-level permissions are enforced under the hood:
from flask import jsonify, abort
from flask_restful import Resource
from flask_login import login_required, current_user
# ...
class AdminAccessControl(Resource):
method_decorators = [login_required, admin_required]
def get_project_data(self, project_id):
# return project data
This hidden flow of logic can be particularly challenging for code-analyzing agents or LLMs to reason about accurately, as the critical security logic isn’t directly visible within the function itself.
Reviewing Detection Success by IDOR Category
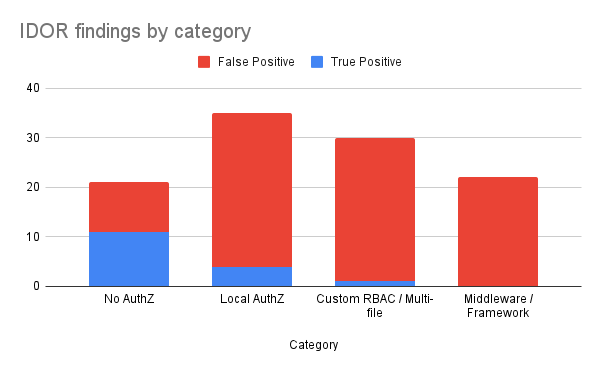
Now that we’ve identified several categories of potential IDORs, let’s look at how the true positive rate (TPR) breaks down across them:
As shown in the chart, the findings are distributed fairly evenly across the four identified categories. However, the majority of true positive results fall within the first two categories: those that do not require cross-file or cross-component reasoning.
True Positive Rate (TP / All Findings)
Anthropic Claude Code (v1.0.32, Sonnet 4)
OpenAI Codex (v0.2.0, o4-mini/high reasoning)
OpenAI Codex GPT-5-codex
1. No verification / protection of the manipulated object at all
68% (11/16)
0% (0/0)
0% (0/5)
2. All protections reside within a small scope (function / file)
50% (3/6)
0% (0/4)
4% (1/25)
3. Custom RBAC logic or the permission check is spread across the app
0% (0/19)
0% (0/1)
10% (1/10)
4. Logic implemented in the middleware, framework, or other places that get called automatically
0% (0/18)
0% (0/0)
0% (0/4)
As we can see from the data:
LLMs perform best when the authorization logic is self-contained, that is, when all relevant checks appear within the same function or file or were not implemented at all. In such cases, the model can easily infer whether access control is missing or incomplete.
False positives increase significantly when the logic is distributed across multiple files or dependent on framework-specific configurations, since the model struggles to trace how user context and access validation flow through the application.
This breakdown highlights how the visibility of context, not just code complexity, strongly influences the LLM’s ability to reason about access control.
Conclusions
This research provided a focused look at how LLMs perform when tasked with detecting Insecure Direct Object Reference (IDOR) vulnerabilities. The key takeaway is that LLMs show real potential, particularly in identifying localized logical flaws that traditional static analysis tools often miss without custom written rules. When all relevant logic is contained within a single function or file, the models can reason effectively and surface meaningful issues.
However, the models are prone to false positives when authorization logic is distributed across multiple files or implemented in less explicit ways. Additionally, non-deterministic findings and inconsistencies between runs, difficulties in deduplication, and a lack of broader application awareness raise questions about false negatives and practical usability at scale. Because of these factors, a human-in-the-loop remains essential. Security engineers are still needed to triage, validate, and interpret the findings, as well as to craft additional prompts that help the model reason across larger contexts.
As LLM technology continues to advance, their role in application security will only grow. While they’re not a replacement for experienced security engineers, they can already act as valuable assistants, augmenting traditional tools and helping uncover issues that might otherwise go unnoticed. By combining LLMs’ reasoning capabilities with human expertise and context, security teams can build more effective workflows and move closer to scalable, AI-augmented vulnerability discovery.
Dive deeper into Security Research or continue reading our featured posts.