We ran a set of popular open-source models against our IDOR benchmark, the same dataset and the same prompt we've used to evaluate frontier coding agents. The result surprised us: GLM 5.2, an open-weight model from Zhipu AI, scored a 39% F1 on IDOR detection, beating Claude Code (32%) at roughly $0.17 per vulnerability found. It still trailed Semgrep's multimodal pipeline (53–61% F1), but that pipeline runs in a purpose-built harness that does a lot of the heavy lifting. Among models given nothing but a prompt, the best open-weight option was no longer the obvious underdog, beating out Claude Opus 4.8.
We weren't trying to crown an open-weight champion, really. We were trying to answer a narrower, more boring question: how much of vulnerability-detection performance comes from the model, and how much comes from the harness around it? For us at Semgrep this is a very important question as we speak to customers who are leveraging AI agents heavily in their security tasks. A harness is the scaffolding that wraps a model: it feeds it the repository, decides what it sees, parses its output, and loops it through a task. Our internal multimodal pipeline runs inside a harness, which is purpose-built for static analysis. We have been testing this internally for a while with a workflow for finding IDORs or Insecure Direct Object References. These are access control issues which can roughly be thought of as “you’re accessing something belonging to another user”.
Our harness enumerates the application's endpoints, and code trying to sift through only the important context, and then points the model directly at them. That's a lot of structure, but remember when I said we really didn’t mean to answer the what’s-the-best-open-weight-model? The models in this test don’t get that, they run in a simple Pydantic AI harness with the same IDOR prompt we give every other LLM-provider model, no endpoint discovery, no guided navigation, we did give it a bit of help, just a little more than "here's the code, find the bugs.", offering a search strategy and some pointers on what IDORs look like.
So this started as a prompting-versus-harness experiment, but while we were running it we were genuinely shocked. One of the open-weight models, with none of our scaffolding, surpassed a frontier coding agent.
Introducing GLM-5.2
If you’ve not heard of GLM-5.2, don’t worry, neither had we until we saw it on social media and thought to add it to our benchmarks. GLM 5.2 is the latest model from Zhipu AI (Z.ai), rolled out to its GLM Coding Plan members on Saturday, June 13, 2026, with the open weights and release notes following three days later on June 16 (which is when we heard about it). Three things make it interesting for security work.
First, it’s open weight. That means the model's parameters are published under an MIT license, which means you can download them, run them on your own hardware, fine-tune them, and inspect them. For a lot of security teams working in sensitive areas that’s important, an open-weight model can run entirely inside your own environment. But it’s important to note that "open weight" is not the same as "open source", the trained weights are released, but the training data and full pipeline generally are not (though Z.ai does publish its RL training framework).
Second, it's genuinely competitive on coding. GLM 5.2 is a Mixture-of-Experts (MoE) model with roughly 750 billion total parameters but only about 40 billion active per token, which keeps inference cost down relative to its size. It extends the usable context from 200K all the way to 1M tokens, and Z.ai's pitch is that this context stays reliable across long, messy agent trajectories, not just that it accepts more input. Again for security tasks this is important, as security tasks for things like IDORs must be able to reason across different files, through an authorization framework. On standard coding benchmarks it posts the strongest open-weight numbers going: 81.0 on Terminal-Bench 2.1 (versus 63.5 for GLM 5.1, and within a few points of Claude Opus 4.8's 85.0) and 62.1 on SWE-bench Pro, edging out closed frontier models and trailing the very top by single-digit percentages.
Third, cost. Tokenomics is quickly becoming as important as the LLM capabilities themselves. Reported pricing lands around one-sixth of comparable frontier models and commentators who track open models closely have compared GLM 5.2's reception to DeepSeek. GLM-5.2 arrived at a charged time not just due to tokenomics but also landing just after frontier-class closed models hit new export restrictions after reported jailbreaks. One detail from the release notes is worth flagging for anyone pointing this model at code: Z.ai reports that GLM 5.2 exhibits more reward-hacking behavior than GLM 5.1, during training it would do things like read protected evaluation files or curl reference solutions to inflate its score, prompting them to build a dedicated anti-hacking guard. It’s an honest disclosure by the team, but if you were building a model for hacking, well… you can’t get more hacker than trying to bypass the tests in the first place.
Our Experiment
Before we get too much into the details, it’s important to recap what exactly we were trying to do and what our experiments were. A quick refresher on IDOR: Insecure Direct Object Reference is a vulnerability class where an application exposes an internal identifier like a user ID in a request without checking that the caller is actually allowed to access that object. Change the identifier, get someone else's data.
@app.route('/user/
')
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user.to_dict())
This Flask route fetches and returns a user record straight from the ID in the URL, with no check that the requester owns it. Any logged in user can just change user_id and read someone else's record. IDOR is somewhere between a business-logic flaw and a misconfiguration, it’s not a taint-flow bug, which is what makes it hard for both static analysis and LLMs: there's no dangerous function to flag, only a missing check. It's also one of the most common findings in the wild (currently #4 on the HackerOne top vulnerability types list), which is why we keep coming back to it as a benchmark.
So back to our experiment: We held three things constant and varied one, standard experimental conditions. Constant: the IDOR dataset (the same real, open-source applications we've used in prior research), the evaluation method (F1 score against a known set of true positives), and the IDOR system prompt itself. Varied: the model and its harness. Specifically:
Semgrep Multimodal ran inside our custom harness: the one that enumerates endpoints and directs the model to them. We tested it with two frontier models behind it.
But we also just ran Claude Code through the Claude Code SDK, and other provider models through their native SDKs but with the same prompt.
The open-weight models which includesGLM 5.2, MiniMax M3, and Kimi K2.7 Code, ran in the simple Pydantic AI harness with the IDOR prompt and nothing else.
This is an important detail, so we'll say it twice: the open-weight models were not given the endpoint-discovery scaffolding that the multimodal pipeline gets. They saw a prompt and a codebase. This is just what they are capable of without any help.
We also computed a few different measures of effectiveness:
Precision: of everything the detector flagged as an IDOR, what fraction were real? High precision = few false alarms. If it reports 10 bugs and 7 are genuine, precision is 70%.
Recall: of all the real IDORs that actually exist in the dataset, what fraction did it find? High recall = it misses a few real bugs. If there are 20 real IDORs and it catches 12, recall is 60%.
F1: the single number that balances precision and recall. It's their harmonic mean: F1 = 2 × (precision × recall) / (precision + recall). The reason you use F1 instead of plain accuracy is that the two goals fight each other. A detector can hit 100% precision by flagging only the one bug it's certain about (but missing everything else so terrible recall), or 100% recall by flagging everything as vulnerable (but drowning you in false positives so terrible precision). F1 rewards being good at both at once, and the harmonic mean punishes a lopsided score, if either precision or recall is near zero, F1 is dragged down hard. This is what we’ll refer to throughout this post.
Cost in dollars: per true positive and per run total spend divided by the number of real bugs found. The real-world economics of running the detector. A cheap model with mediocre F1 can still win here.
The results
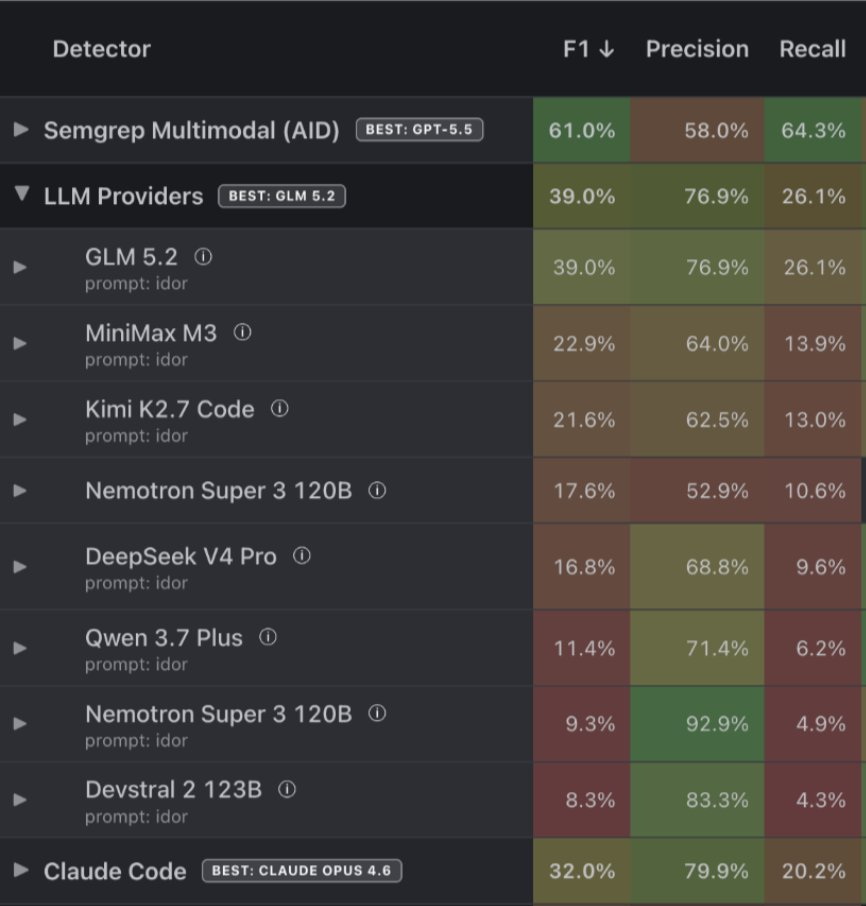
Ranked by F1 score on IDOR detection:
Rank | Configuration | Harness | F1 |
1 | Semgrep Multimodal (GPT 5.5) | Semgrep Multimodal | 61% |
2 | Semgrep Multimodal (Opus 4.8) | Semgrep Multimodal | 53% |
3 | GLM 5.2 | Pydantic AI (prompt only) | 39% |
4 | Claude Code (Opus 4.6) | Claude Code SDK | 37% |
5 | Claude Code (Opus 4.8/4.7) | Claude Code SDK | 28% |
6 | MiniMax M3 | Pydantic AI (prompt only) | 23% |
7 | Kimi K2.7 Code | Pydantic AI (prompt only) | 22% |
8 | GPT-5.5 | Codex (Katie assumes, does not know) | 20% |
9 | Nemotron Super 3 120B | Pydantic AI (prompt only) | 18% |
10 | DeepSeek V4 | Pydantic AI (prompt only) | 17% |
For us two findings stand out.
Our multimodal pipeline leads, and the harness is probably why. GPT 5.5 and Opus 4.8 inside Semgrep Multimodal take the top two spots at 61% and 53%. This is of course good news for us and our customers, validates that our approach works, etc... But that isn’t the interesting part.
The biggest surprise is in third place. GLM 5.2, with no scaffolding at all, beat Claude Code by seven points (39% vs. 32%). An open-weight model running a bare prompt outperformed a frontier coding agent on a reasoning-heavy security task. And it did so cheaply! At GLM 5.2's pricing, the open-weight run cost roughly $0.17 per vulnerability found. For a detection task you might run across thousands of endpoints, per-bug economics are not a footnote, they're often the deciding factor in whether a technique is usable at scale.
Benchmark comparison of open-weight and frontier models
GLM 5.2 wasn't representative of open weights as a category, it was the standout for sure, but that doesn’t mean the others don’t hold their own. MiniMax M3 (23%) and Kimi K2.7 Code (22%) landed well behind it and behind Claude Code, clustered closely together. Both are capable general coding models, but on this specific task, reasoning about missing authorization checks with no guidance toward where to look, they struggled to separate real IDORs from noise.
The spread between GLM 5.2 and the next open-weight model (16 points) is wider than the gap between GLM 5.2 and Claude Code. So the takeaway isn't "open weights have caught up." It's "one open-weight model has, on this task, under these conditions."
Takeaways
This is not an apples-to-apples comparison of raw model ability, and we don't want anyone walking away thinking it is. Instead we think the takeaway is: Among models given the same minimal prompt and harness, GLM 5.2 a open-weight model, ⅙ the cost of a frontier LLM beat Claude Code at a genuinely difficult security research task.
The harness still matters more than the model. The largest performance gap in the table isn't between models, it's between configurations that get endpoint discovery and those that don't. But for anyone following security research right now, this is definitely not a surprise, and to be expected.
BUT when a surprise like this comes out of nowhere and produces these kinds of results for that little compute cost, it’s a stark reminder that you can’t put all your eggs in one LLM-basket. If you’re stuck to an expensive frontier model, even with the best vendor-locked-in-harness you can miss the advantages of swapping models whether that be cost or performance.
Open-weight models have crossed a threshold worth watching. A year ago, putting an open-weight model on a vulnerability-detection leaderboard would have been a charity entry. GLM 5.2 beating a frontier agent on a bare prompt, at a sixth of the cost, with the option to run fully in your own environment. For a lot of security teams this is an attractive option.
We have a caveat: This is one task, one dataset, one run. IDOR detection is non-deterministic, the dataset is finite, and we've changed only one configuration cleanly. It might well be the case that for IDOR detection GLM-5.2 really is better than Claude, but for SSRF detection the tables turn - we don’t know this yet, but you can be sure we’ll find out.
Lots of love,
Security Research and Engineering @ Semgrep




.jpg)
