


When we first started experimenting with AI for vulnerability detection, the results were promising. We could find interesting issues and build compelling demos. But demos are easy. The real challenge was turning these experiments into something you could rely on in production.
To get there, we had to answer a few hard questions:
How do you get false positive rates low enough that engineers actually trust the results?
How do you introduce more determinism so results are stable and repeatable from scan to scan?
How do you keep costs under control when using large language models?
How do you performantly scan real codebases including like large monorepos, not just small demo apps like juice-shop?
This post explains how we approached each of these problems and why we built Semgrep Multimodal, which combines AI reasoning with rule-based analysis for detection, triage, and remediation, as a result.
Reducing false positives by adding context
One of the biggest sources of false positives in AI-powered detection is missing context. Code often makes sense only if you understand how the system is designed and what assumptions the development team made.
To address this, Semgrep’s AI-powered detection supports Memories: user-provided instructions that guide how the AI reasons about a codebase. Memories are persistent and scoped to the user or organization.
For example, one beta customer had a backoffice user profile that was explicitly allowed to access certain sensitive objects. Without that knowledge, the AI repeatedly flagged these access privileges as authorization issues. Once the user added a memory explaining that this profile was trusted and intentional, those findings stopped appearing. This led to a major reduction in noise with no loss in real signal.
Semgrep also supports uploading context documents up front. Many teams already have threat models, design docs, or documented security assumptions. Instead of requiring users to restate that context repeatedly, we allow it to be incorporated directly into analysis. This aligns the model’s reasoning with how the system actually works.
Adding determinism, reducing cost, and scaling with static analysis plus AI
We set out to build a vulnerability detection solution with two complementary strategies: use the advanced code analysis that Semgrep is known for, and evaluate the intent and context of the code and its security properties using the human-like capabilities of ever-improving large language models.
At a high level, the system works by using static analysis to narrow down where the model should look, and then applying the model in a much more targeted way.
This starts with candidate generation. Using pattern matching along with control flow and data flow analysis, Semgrep identifies parts of the codebase that are likely to be security-relevant. Instead of trying to reason about everything, it focuses on regions where something interesting is actually happening.
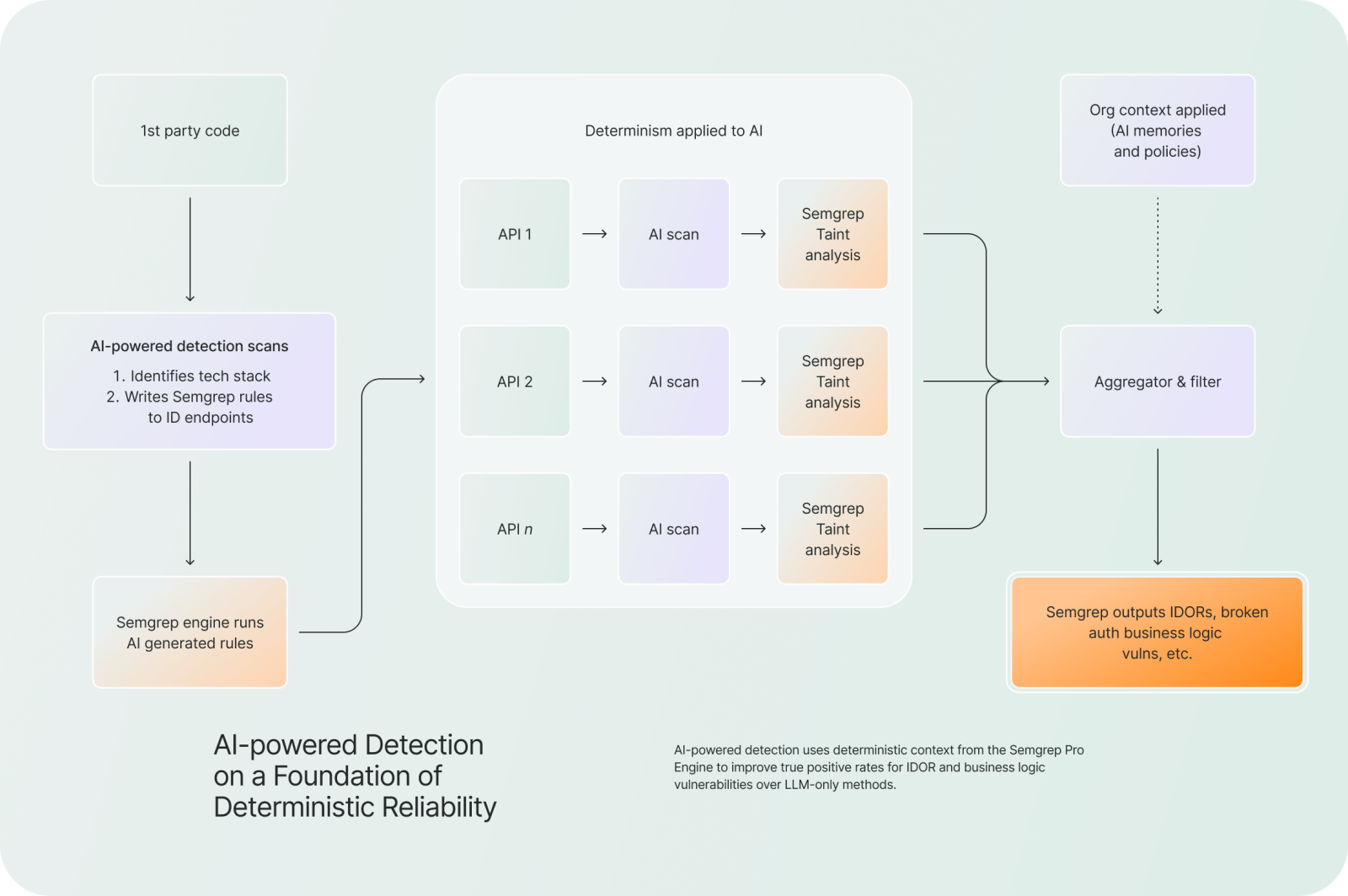 From there, it builds a focused view of each candidate. Rather than passing entire files to the model, Semgrep constructs a slice of the program that captures just the context needed to understand the behavior. That includes the relevant functions and call paths, how data flows through the code (sources and sinks), and any surrounding logic that affects execution.
From there, it builds a focused view of each candidate. Rather than passing entire files to the model, Semgrep constructs a slice of the program that captures just the context needed to understand the behavior. That includes the relevant functions and call paths, how data flows through the code (sources and sinks), and any surrounding logic that affects execution.
The model is then asked to evaluate these slices. Because the input is structured and constrained, it can spend its effort reasoning about higher-level questions: what the developer intended, what security properties should hold, and whether the behavior is actually exploitable in practice.
Finally, Semgrep normalizes and filters the results. This includes deduplication, consistency checks, and additional filtering using both static signals and learned heuristics to reduce noise.
This structure ends up being critical. By using static analysis to guide the model, we avoid many of the issues that come from running an LLM directly over raw code.
One immediate benefit is cost. Since AI is only evaluating high-signal regions, we avoid sending large amounts of irrelevant code to the model. That keeps token usage under control and makes it feasible to scan large repositories. We find that Semgrep Multimodal produces true positives results at 37% lower costs compared to finding through LLMs alone.
It also improves consistency. If you run a model directly over a codebase, it’s common to get noticeably different results from one run to the next—findings appear and disappear, and it’s hard to know what to trust. By contrast, our candidate generation step is stable, so the same code produces the same set of regions to evaluate every time. Any variability is limited to small, localized decisions by the model. In practice, this means Semgrep Multimodal consistently finds the same issues across runs, which increases effective recall (fraction of true positives found out of all true positives) on any given scan and makes the results much easier to trust.
Just as importantly, it improves precision. Because the model sees complete control and data flow slices, it’s much less likely to hallucinate missing paths or misinterpret partial snippets. Instead of flagging patterns in isolation, it can reason about how the code actually behaves at runtime.
Reducing false positives with incremental analysis
Our initial hybrid system significantly improved recall—but also introduced additional false positives by expanding the search space.
To address this, we leveraged Semgrep’s incremental analysis capabilities.
Instead of re-evaluating the entire codebase on every scan, it:
Tracks which parts of the code changed
Uses control flow and data flow analysis to identify downstream impact
Restricts model evaluation to affected regions only
This has two important effects:
Eliminates stale or irrelevant findings
Prevents re-analysis of unchanged code that previously produced noise
In practice, this reduced false positives from the initial approach by 90%, resulting in a false positive rate lower than the model-only baseline.
Results
We evaluated this approach on a corpus of 90+ vulnerabilities across four widely used open source repositories.
Compared to a model-only baseline (Claude Opus 4.6), the hybrid system achieved:
8.2x more true positives (coverage)
54% reduction in false positive rate
Lower variance across repeated runs
Normalized TPs | FP Rate | |
Claude | 100% | 41% |
Semgrep AI-powered Detection | 823% | 19% |
These results highlight the core advantage of combining program analysis with AI:
we expand coverage without sacrificing precision or reliability.
Conclusion
AI is powerful, but using it effectively for security detection requires more than just throwing code at a model.
By combining:
Static analysis for structure and scale
User-provided context for accuracy
Targeted AI reasoning for semantic understanding
Semgrep Multimodal delivers results that are trustworthy, scalable, and cost-effective.
This approach enables teams to find real logic issues in real codebases—without drowning in noise or dealing with unpredictable results.


.jpg)
