Making Semgrep rip: How Ripgrep inspired us to shave hours off (some) scans
Semgrep 1.162.0 fixes a file targeting bottleneck that caused scans on large repos to take hours. By replacing expensive regex calls with string comparisons and a constant-time hash table lookup, P99 diff scan times dropped from ~60 minutes to under 12, with one customer repo improving from 7.5 hours to under 2 minutes.
Ben Kettle
June 10th, 2026
TL;DR: Semgrep's file targeting step, which filters files against ignore patterns before scanning, had edge cases which could cause some scans to take hours. Tracing data showed the culprit: for large repos, Semgrep was making millions of regex calls to match file paths against ignore patterns. We fixed this by replacing most regex lookups with equivalent string comparisons and building a hash table index to check arbitrarily many patterns in constant time. With these changes, a customer repo that previously spent 7.5 hours on the problematic file targeting step now spends under 2 minutes. Across our fleet, the 99th percentile diff scan duration dropped from nearly an hour to under 12 minutes. These improvements shipped in Semgrep 1.162.0 and are available in both the open-source Semgrep CE and Semgrep Pro.
Semgrep supports ignores from .gitignore, .semgrepignore, our web backend, or from a list of default ignores. These can be customized to tune findings: if you don't care about findings in test files you can exclude tests/, if you don't care about findings in generated protobuf code you can exclude protos/, or if you know that you only use Python for scripting and never deploy it you can exclude .py. Semgrep ignores certain low-signal files like .min.js out of the box.
To handle these ignores, one of the first steps of a Semgrep scan is file targeting. This step collects all files in the project and applies gitignore and semgrepignore filters to narrow them down to the set of targets that should be scanned.
Unfortunately, tracing data from our scanning fleet showed that this file targeting step was taking inordinately long on many repos. While the median duration of the file targeting step is only 30ms, the 90th percentile duration for the step is around a minute, the 99th percentile is in the tens of minutes, and the maximum is in hours.
While most scans are not affected, this slowness has a real effect on both customers and Semgrep's bottom line. Customers depend on Semgrep to quickly scan their developers' PRs and, with Semgrep Managed Scans, Semgrep pays for far more compute minutes on beefy scan instances than we feel this trivial pattern matching deserves.
What is .gitignore? What is .semgrepignore?
Semgrep respects both .gitignore and .semgrepignore: if a file is ignored by either of these, it will not be scanned. Git reads .gitignore files from the filesystem and uses the patterns contained inside to determine which files should be versioned by git. Semgrep follows the .gitignorespecification for its own ignore file, .semgrepignore, that allows users to exclude files from scans that they do not want excluded by Git. Semgrep also supports ignoring files from our web application, allowing customers to customize their results without needing to commit changes to every repository, and by default excludes files with high scan costs and low security importance like minified Javascript files.
Today, Semgrep relies on git ls-files to enumerate files that pass .gitignore filtering. This is performant, since Git can use its internal index to produce this list quickly. But there is no such index for Semgrepignore patterns, and storing one would be challenging because Semgrep does not store state in the filesystem like Git does and makes an effort to avoid storing customer data where possible. Instead, we match Semgrepignore patterns inside Semgrep in OCaml code that compiles Gitignore-compatible patterns to Regex and pairwise matches patterns with paths to identify the set of included files.
Traces identify the culprit
While continuous profiling described by Austin in the previous posts (Announcing Pyro Caml: A Continuous Profiler for OCaml and How Semgrep Cut Taint Analysis Time by 75%) is the gold standard for pinning down performance problems across the scanning fleet, traces provide unmatched visibility into individual scans. At Semgrep, we trace every single scan that runs on our infrastructure via OpenTelemetry, providing function-level visibility into the wall-clock runtime of every scan that we can slice and analyze by customer, repository, or any number of other dimensions.
This tracing data showed us that the top 5% or so of our customer scans were unacceptably long. Our internal target is for 95% of diff scans to run in under 5 minutes and we were not meeting that target. Digging into the problematic traces, we found that file targeting, and in particular Semgrepignore filtering, was a major contributor to this too-long diff scan time.
As an example, this particularly egregious trace shows an 8.5-hour long full scan that spends 7.5 hours filtering paths for file targeting!
Semgrep ships with around 20 default ignore patterns and allows customers to add more. At minimum, then, we run 20 regex patterns for each file in the scanned project. In practice, we run many more: to match Gitignore semantics, we run patterns not only on the whole path but also on every prefix of the path: for the file a/b/main.py, we will run the ignore patterns first on a, then on a/, then on a/b, then on a/b/, and finally on a/b/main.py itself.
Repository
# files
# PCRE calls
kubernetes
29230
5780062
etcd
1419
160710
rust
57818
5507260
chromium
597967
124173852
Clearly, this is a lot of regex.
Removing Regex, Referencing Ripgrep
The data above show that for the 22 default Semgrepignore patterns, we run about 100-200 PCRE patterns for each file—a total of millions on common OSS repos. None of these repos are excruciatingly slow locally, but we’ve learned long ago that open source repos are nowhere near representative of customer repos. Traces of customer repos show the filtering step—which essentially does nothing more than iterate over paths and run regex patterns—taking hours in the worst case. While PCRE, the C library that we call out to in order to run our Regex matching, is well-optimized, whatever we can do to reduce the number of regexes we need to run seems promising.
Ripgrep, the famously fast text search tool, respects .gitignore—so it must have a performant way to handle ignore patterns. Indeed, Ripgrep implements gitignore filtering and its globset crate goes to significant length to skip as many regex runs as possible. They abstract gitignore patterns above Regex, allowing them to implement matching without running Regex for many classes of patterns:
#[derive(Clone, Debug, Eq, PartialEq)]
pub(crate) enum MatchStrategy {
/// A pattern matches if and only if the entire file path matches this
/// literal string.
Literal(String),
/// A pattern matches if and only if the file path's basename matches this
/// literal string.
BasenameLiteral(String),
/// A pattern matches if and only if the file path's extension matches this
/// literal string.
Extension(String),
// <Prefix and Suffix definitions trimmed>
/// A pattern matches only if the given extension matches the file path's
/// extension. Note that this is a necessary but NOT sufficient criterion.
/// Namely, if the extension matches, then a full regex search is still
/// required.
RequiredExtension(String),
/// A regex needs to be used for matching.
Regex,
}
Most of these alternatives are extremely simple, as described in the inline comments. Many patterns look for a specific string in a specific part of the path, whether it's the whole path (the Literal strategy), the last segment (the Basename strategy), or the extension (the Extension strategy). Other patterns may be more complicated, but still have simple components: the RequiredExtension strategy handles arbitrarily complex patterns that end with something like *.ext—no matter how complex the rest of the pattern is, when matching a file against the pattern we know immediately that if the extension does not match the one from the pattern, it is impossible for the rest of the pattern to match and we can skip running the full regex. Ripgrep also implements Prefix and Suffix strategies, not shown above, that handle an even broader set of patterns.
Conveniently, these four strategies cover all of Semgrep's default ignore patterns. Most of the default patterns are things like .git, build/, or node_modules, all of which fall under BasenameLiteral. Applying the above strategies, these can each be evaluated with no regex at all, just a single string comparison. Only two patterns in our default ignore, .min.js and _test.go, fall outside the BasenameLiteral strategy but still within the index: those patterns can use the RequiredExtension strategy to reduce, but not eliminate, Regex calls.
The most obvious thing to do is simply to replace each Regex comparison with the optimized match strategy, replacing most Regex lookups with an OCaml-native string comparison. Indeed, implementing this swap showed a substantial speedup: doing file targeting with the default Semgrepignore patterns on kubernetes took 34s with no optimization and only 17s with the Literal, BasenameLiteral, Extension, and RequiredExtension string-equality strategies implemented (we skipped Prefix and Suffix because the matching code gets more complex).
34s to 17s is a pretty solid 2x improvement, but for our customers who were waiting hours for file targeting to complete, it isn't enough. Half of hours is still hours, and hours is way too long.
However, it doesn't seem like we can reduce work for each match any further: each path segment / pattern pair is now cheap. If we want to make it faster, we likely need to reduce the number of matches we attempt. Luckily, we can crib from Ripgrep for this, too.
Matching n patterns in constant time
When thinking about these regex patterns as regex patterns , it's hard to come up with a way to make this better. But the four matching strategies that we implemented in the first attempt—Literal, BasenameLiteral, Extension, and RequiredExtension—all rely on a simple string equality check to determine if a given path matches a given pattern. This collapses the problem into a much more common one: in the common case, determining if a pattern matches for a file now just requires checking if the path matches any of the strings corresponding to path patterns, if the basename matches any of the strings corresponding to path patterns, and if the extension matches any of the strings corresponding to extension patterns. In our first attempt, we did this by iterating over the full set of patterns and checking string equality against each pattern's string equivalent.
However, I learned in my first computer science class that if you have a list of strings A and you want to find out which ones are present in another list of strings B, you shouldn't iterate through both lists and check each pair. Instead, you should build a hash table out of B and then look up each string from A there. This hash table allows determining if a string matches any of the strings from B in about the same amount of time that it would take to check if a single pair of strings are equal, so although it takes a bit of time to build this hash table and a bit of extra memory to store it, this effort is probably worth it if you’ll need to look up items in B more than a few times. In our case, where B is the lists of patterns, we need to look up items in B hundreds of thousands of times.
Building hash tables is exactly what Ripgrep does[1], and it's exactly what we'll do. In particular, we need one hash table for each strategy: looking up extensions and matching patterns for basenames, for example, would violate the correctness of the optimization. Instead, we need to match path basenames against basename-shaped patterns, literals against literal-shaped patterns, and so on.
Gitignore semantics require that patterns be evaluated level-by-level, so we create these hash tables—together referred to as the index—for each Gitignore level. In most cases, there is only a single level holding the default ignores, but when scanning projects that use .semgrepignore at various levels of the directory tree we will construct one index for each.
Regardless of the number of patterns present, this index allows us to evaluate a path against all the patterns in just four hash table lookups, plus any calls to Regex that are required for unsupported patterns (in most cases, no such calls are required). With our default ignores, all but one of these hash tables are empty, further speeding things up.
Repository
# files
# PCRE calls before
# PCRE calls after
kubernetes
29230
5780062
11209
etcd
1419
160710
799
rust
57818
5507260
17
chromium
597967
124173852
12692
Running scans on the same open-source repos as before, we see many-fold improvements in the number of PCRE calls we make. Although it isn’t a direct measure of performance, this is definitely a good sign.
Results
Local testing yielded a much more promising speedup for this hashtable. Where the kubernetes repo took 34s unoptimized and 17s with our first attempt, with these indexes in place it took only 3.4s! I'll certainly accept a 10x speedup, but we've already established that OSS repos are amazingly unrepresentative of customer ones.
So let's see what happened with those hours-long scans that brought us here in the first place.
Looking back at the egregious customer repository from earlier, which previously spent 7.5 hours of an 8.5-hour scan time in file targeting, we see that overall scan time is now just 1 hour, with a small fraction spent in file targeting.
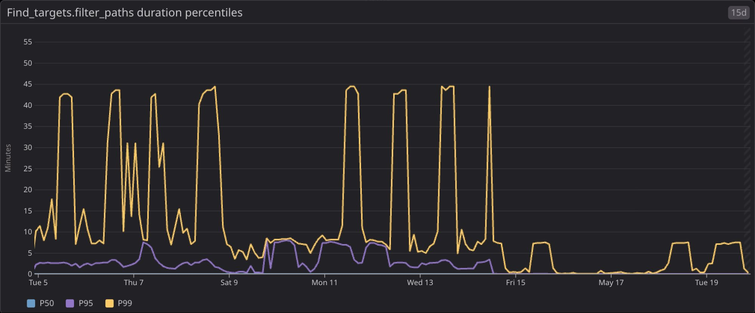
This generalizes across the slowest 5% of scans: the 99th percentile duration of the step dropped from 8 minutes with spikes to 45 minutes to now just a few seconds, with spikes to 7 minutes.
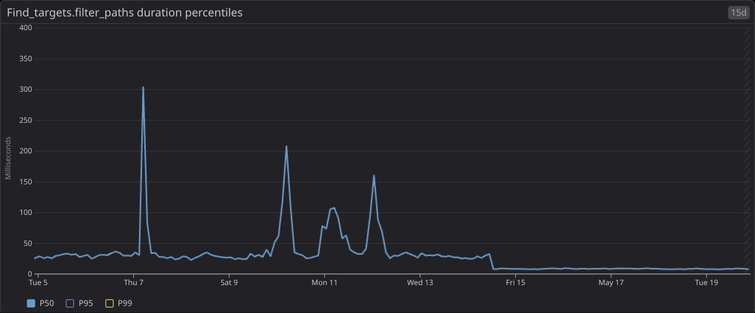
This doesn’t only affect the most expensive scans: the median saw a marked drop as well. While the median duration was previously around 30ms with spikes to 200ms, after these changes the median duration for this step is very consistently around 8ms.
Customer repository
Median time before
Median time after
1
7h 14m
1.5m
2
3h 5m
33m
3
2h 17m
43m
4
2h 3m
11m
5
1h 21m
18s
Some of our most problematic repos saw surprisingly large speedups. One customer's repository dropped from a consistent 7 hours spent on this step every scan to just 90 seconds. Another saw a drop from 1.5 hours to 18 seconds. Certain long-running repos saw a smaller drop, with one going from 3 hours pre-optimizations to 33 minutes afterwards and another going from 2.5 hours to 45 minutes post-optimizations. Overall, our longest-running repos overwhelmingly saw at least 5x, and frequently 10x, speedups on this part of the scan.
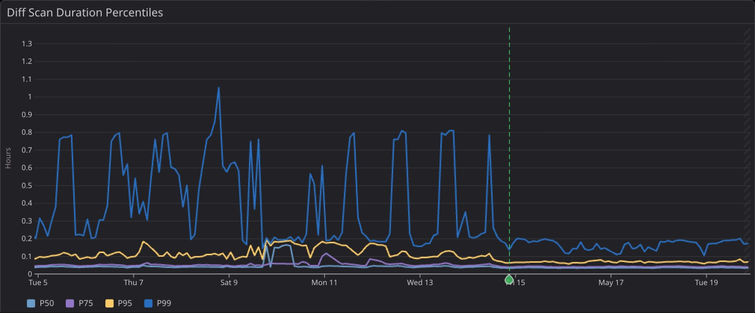
Of course, customers don't care about how long file targeting in particular takes. But this change had a notable impact on the longest diff scans across our fleet. While the p99 duration for diff scans used to frequently jump to nearly an hour, after these changes were released the p99 duration has not crossed 12 minutes. The p95 duration has seen less drastic, but still notable, improvements: scans at this percentile previously ranged from 6-12mins and now are quite consistent at 4 minutes. As mentioned in the last post, the drop in variability is especially valuable internally, as it allows us to more easily identify future performance regressions as well as future performance improvements.
What's next
We are thrilled with these results and excited that our largest customers have started to see the benefits. We've seen huge improvements across the board, with repos that used to take hours to complete file targeting now taking minutes. But minutes is still longer than we'd like to spend on this step, and for certain repos we still spend tens of minutes (but not hours, anymore!). There is more we can do to optimize this function, both algorithmically and otherwise.
Algorithmically, our approach of iterating over a flat list of paths fundamentally leads to some repeated checks that could be avoided with a more tree-shaped algorithm. Separately, the same path filtering function also makes two system calls for each file to verify that they are regular files. Across many files, these system calls can add up[2] and local testing showed that they are responsible for the majority of the remaining filtering time (20s of 28s total) when scanning Chromium.
Ultimately, these performance improvements delivered a meaningful improvement to diff scan times for many of our users and with these improvements, even for large repos the majority of scan time is spent on Scanning. Just the way it should be.
These changes, along with other performance improvements, are live in version 1.162.0 of both Semgrep CE and Semgrep Pro.
Note that Ripgrep also supports Prefix and Suffix strategies, which are not as simple as a single string equality check. Instead, Ripgrepuses theAho Corasick string search algorithm that constructs a finite state machine from the patterns and steps through the input to produce all matches. Since our default ignores were covered by the simpler strategies, we decided to stick to those and rely on PCRE for these prefix and suffix patterns.
The impact of these syscalls is likely amplified in our production environment, which uses Gvisor to sandbox scans. Gvisor intercepts and inspects every syscall to ensure that it does not allow a sandbox escape.

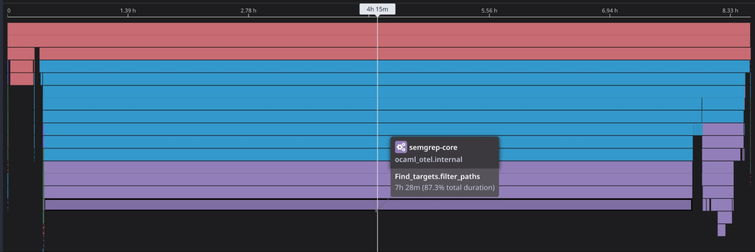
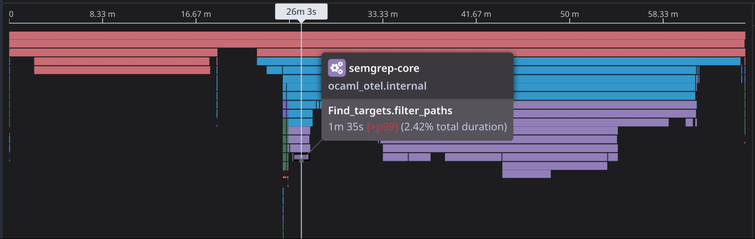 Looking back at the egregious customer repository from earlier, which previously spent 7.5 hours of an 8.5-hour scan time in file targeting, we see that overall scan time is now just 1 hour, with a small fraction spent in file targeting.
Looking back at the egregious customer repository from earlier, which previously spent 7.5 hours of an 8.5-hour scan time in file targeting, we see that overall scan time is now just 1 hour, with a small fraction spent in file targeting.