



tl;dr:
Our benchmark scores AI vulnerability detection on the metrics of precision, recall, consistency, and cost per true positive
We find that Semgrep Multimodal finds 3.5x more true positives than a tuned guided prompt, at similar precision and lower cost per finding.
This edge is enabled by Semgrep Multimodal using deterministic analysis to inform an AI model as to where to look (models miss up to 90% of endpoints alone); the model then reasons about what’s exploitable.
A security engineer points a frontier model at their main repository, asks it to find vulnerabilities, and gets back a list of findings. The reasoning in each one is sharp. They fix the findings and move on. A few weeks later, a pentester reviews the same service and reports a handful more, all in endpoints the model never flagged. While the model found legitimate issues, it missed most of the code.
In Operationalizing AI-Powered Detection, we explained how we turned AI-powered detection from a compelling demo into something teams can run in production: use static analysis to decide where a model should look, then give it focused slices of code to reason about. In developing AI-powered detection in Semgrep, we asked ourselves something every team considering AI for security work eventually asks: can AI reliably find vulnerabilities in the code? Most vendors will simply say yes. A useful answer needs a benchmark platform.
So we built one, and we run it continuously. This post covers what it measures and what it says about the latest generation of models.
A single number isn’t enough
Most AI security comparisons pick one figure (usually “did it find the bug?”) and stop there. In production, that figure hides most of what matters. A scanner that finds everything but buries the team in false positives doesn’t get used. One that's precise but misses two-thirds of the attack surface isn't safe. One that's low in noise and catches many bugs but costs many times more per real finding doesn't survive a budget review.
Our benchmark team continuously measures four things against a corpus of open-source repositories where our security research team has established ground truth, so we know what's actually there to find:
Precision: the share of reported findings that are real. Noise erodes trust faster than almost anything else.
Recall: the share of real vulnerabilities found. Low recall stays invisible until an incident makes it visible.
Consistency: whether the same code produces the same findings run over run. Non-determinism is one of the most common complaints we hear about scanning with raw models.
Price per true positive: not the cost of a scan, but the cost of each real, actionable finding.
On the last point: “price per scan” is the wrong way to think about the economics of AI detection. A scan that’s cheap to run but misses most of your vulnerabilities isn't actually cheap: the real cost shows up as bugs that ship and leave you exposed. A better question is how much risk you retire for each dollar spent, and two systems running the identical model can land in very different places on that question depending on how they handle coverage, context, and attention.
Harnessing AI’s capabilities
When we compare approaches, we often hold the model and change the harness around it: the program analysis tools, the candidate selection, the context construction, the filtering, and the orchestration that decides what the model sees and when. Semgrep Multimodal is a harness in exactly this sense. When you scan a project, the system built around the model does the work of finding the security-relevant code, directing the model agent to individual portions of source code, and reconciling the results.
The harness turns out to matter more than the model version. A newer model does help, at the margin. The scaffolding around it is what meaningfully changes the result.
This is most clearly seen with coverage. Models are remarkably good at judging whether a specific endpoint is exploitable. They are bad at deciding where to look. Hand a frontier model a repository and ask it to find vulnerabilities; it will evaluate the endpoints it happens to notice (and fail to notice up to 90% of them). You can't find a vulnerability in code you never analyzed.
Semgrep handles that part deterministically. Its program analysis techniques enumerate the endpoints and sinks in a codebase comprehensively and repeatably, because enumeration is exact and not a probabilistic guess. Then we hand those locations to the model one at a time. The model’s reasoning is unchanged. Its coverage is transformed. That single choice, deterministic enumeration feeding model reasoning, is the biggest driver of why the recall numbers below look the way they do.
Benchmark results
We compared Semgrep Multimodal against two other ways of using the same underlying model, Claude Opus 4.8, the most capable security-grade model generally available from Anthropic right now, since Fable 5 is designed to switch to Opus 4.8 for security tasks. We also included GPT 5.5 results for comparison. The first is a guided prompt: Opus 4.8 and GPT 5.5 asked directly to find the target vulnerabilities. We steel-manned this one, tuning the prompt to be as effective as we could make it rather than starting from a naive baseline. The prompt includes a description of what to look for, what those things typically look like, common patterns we see, things to skip, and a recommended investigation strategy. The second way of using the same underlying model is through Claude Security, Anthropic’s own harness around Opus 4.8.
Detector | F1 score | Precision | Recall | Cost / true positive |
Opus 4.8 (guided-prompt) | 21.4% | 71.4% | 12.6% | $0.77 |
GPT 5.5 (guided-prompt) | 16.3% | 68.8% | 9.2% | $0.68 |
Claude Security (Opus 4.8) | 20.4% | 63.6% | 12.2% | $72.55 |
Semgrep Multimodal (Opus 4.8) | 53.5% | 69.4% | 43.5% | $0.62 |
F1 score is the harmonic mean of precision and recall.
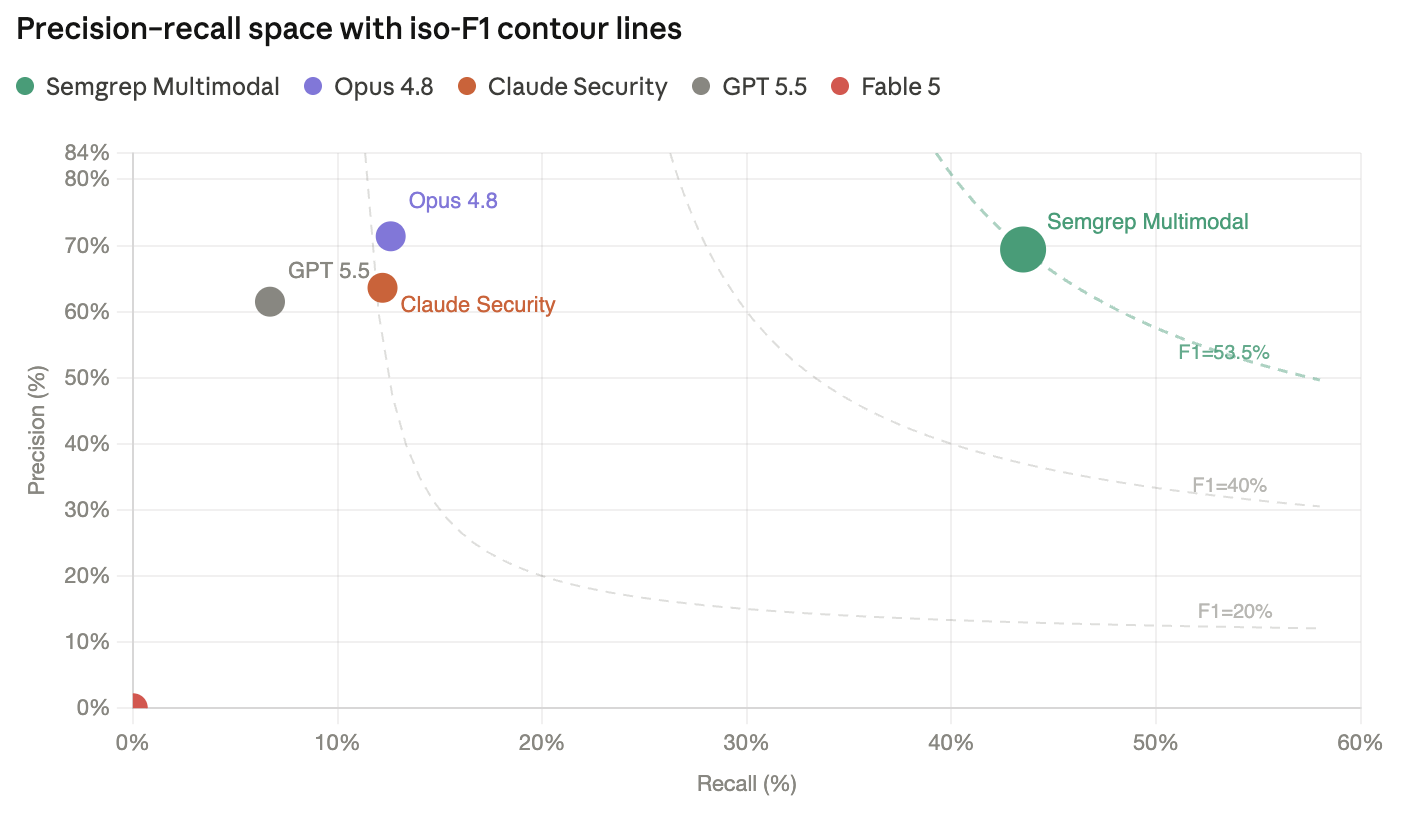
Of note:
Precision is roughly the same across all four.
Recall: Semgrep Multimodal finds 3.5x more true positives than the guided prompt running the identical model, because it looks at more of the right places.
Cost: At $0.62 per true positive versus $0.77 for the guided prompt, Semgrep Multimodal is cheaper for each real finding, because it doesn’t burn tokens re-reading code to decide where to start.
A harness can have downsides. Claude Security performs with roughly the same precision and recall as the guided prompt, but at $72.55 per true positive, over 100 times the cost per vuln of Semgrep Multimodal on the same model. Wrapping a model in scaffolding doesn’t automatically make it efficient.
Improving recall for standalone model use
We’ve run this comparison across three generations of Opus (4.6, 4.7, and 4.8). For each, Semgrep Multimodal delivers between three and eight times the recall of the model on its own, at a lower cost per true positive, with comparable or better precision.
Earlier benchmarking results showed an improvement at the high end of that range, around 7-8x. The most recent run shows 3.5x. The gap narrowed because we improved the prompt we benchmark against. We made Opus and GPT better at the task, roughly doubling their recall, and then measured Semgrep against that stronger baseline. A comparison that only flatters one side when you weaken the other side isn't worth running.
Benefiting from every generation’s improvements
The numbers above describe today's best models, and they'll change with the next release. The durable part is the principle underneath them: let deterministic program analysis do the work models are unreliable at, finding every place worth examining, repeatably, and let the model do the reasoning only it does well.
A better reasoner inside a better-structured workflow gets you more than either does alone. The endpoint identification, the reachability analysis, and the rules that decide where to look don't get retired as models improve. They are what turn a stronger model into a detection system you can put in front of your developers and trust.
Clint Gibler, of tl;dr sec fame and Cyber Lead at OpenAI, framed it well:
💡 Here’s how I see it: the foundation model labs try to convince you that “all you need is the model” and security vendors (or individuals) argue “it’s all the scaffolding.” Ultimately, I believe the truth is: the model, the prompt(s)/Skills, scaffolding/architecture, and how much you’re willing to spend all matter. Improving each gets overall better performance. Improving the model can get you the same or better results with removed (or less) scaffolding, and improved scaffolding on top of better models will yield even better results (more true positives, fewer false positives/negatives).
At the end of the day, it all distills down, like most things in security, to: how much risk reduction are you getting at what price? My $0.02 at least.
(from tl;dr sec #332)
For the architecture behind these results, the earlier post walks through how candidate generation, program slices, and incremental analysis fit together. If you'd like to see Semgrep Multimodal run against your own code, create a Semgrep account to try it or request a demo.


