Year to date, Semgrep Assistant has triaged ~60% of new SAST findings for our customers, filtering out false positives before security teams ever see them. When users audit Assistant's triage history, they agree over 96% of the time.
In simpler terms, Assistant can take a lot of work off your plate, and it's accurate enough to be trusted with that work.
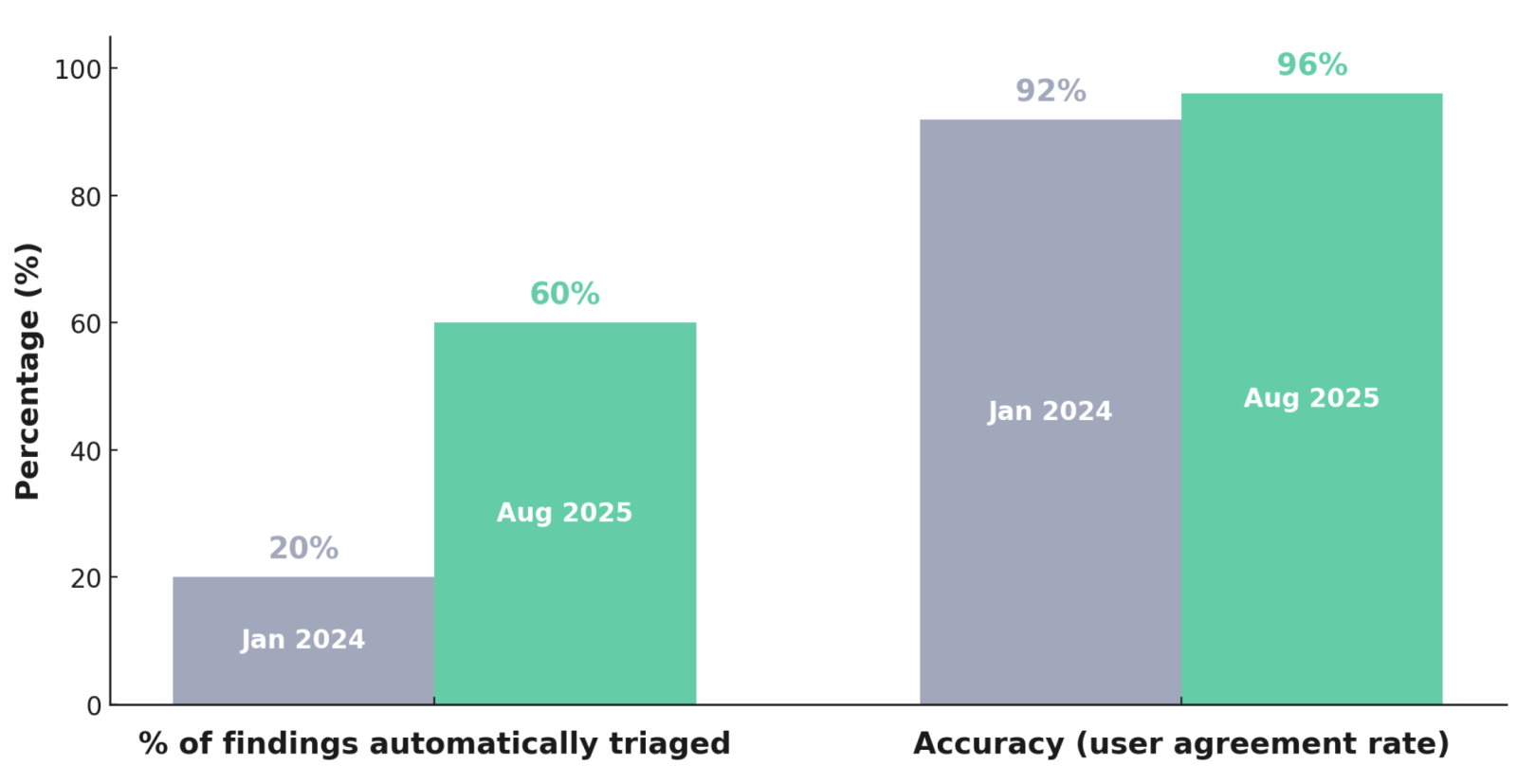

The 96% figure isn’t derived from an internal benchmark or methodology — it’s the real-world agreement rate. In other words, it’s the percentage of Assistant triage decisions that actual customers, reviewing real findings in their code, confirm as correct.
"There were times where Assistant just felt magical."
- Allan Reyes, Staff Security Engineer @ Vanta
"This level of contextual understanding of the intent and effect of the code was amazing to see, comparable to the analysis I'd expect of my security engineer SMEs with an understanding of our company-specific nuances."
- Ari Kalfus, Product Security @ DigitalOcean
The false positive problem
Semgrep is regarded as a leader in accuracy without Assistant turned on. With this baseline in mind, the data here suggests something eye-opening: for many security teams, more than half of the SAST findings they see are false positives.
If you're not a security engineer, it's helpful to think of code scanning tools as smoke alarms. If a smoke alarm goes off while you’re cooking, it isn’t malfunctioning - it just lacks the context to distinguish real risk (you left the stove on) from potential risk (you overcooked dinner).
Code scanners are the same way: they flag potential risks via pattern matching, but they often require local code context to determine if something poses a real threat. Since small AppSec teams have to secure the code of 1000+ developers, they also lack the local knowledge and context to triage effectively.
.png)
This context/knowledge gap is why developer <-> security workflows are often frustrating.
Making Assistant accurate enough to do real work
Giving LLMs more Semgrep
In our recent blog, we explained how giving LLMs local security context and the ability to use Semgrep as a tool helps AI “think” like a security engineer. Our goal is for Semgrep to be the foundation that enables any LLM to do security work 10x more effectively and reliably, whether it’s ChatGPT, Grok, Gemini, or Claude. Essentially, if a model gets 1% better at X security task, we want it to get 10% better when plugged into Semgrep.
Here’s a high level diagram showing the data and tools we dynamically pass to the LLM (not just for autotriage, but all of our AI capabilities):
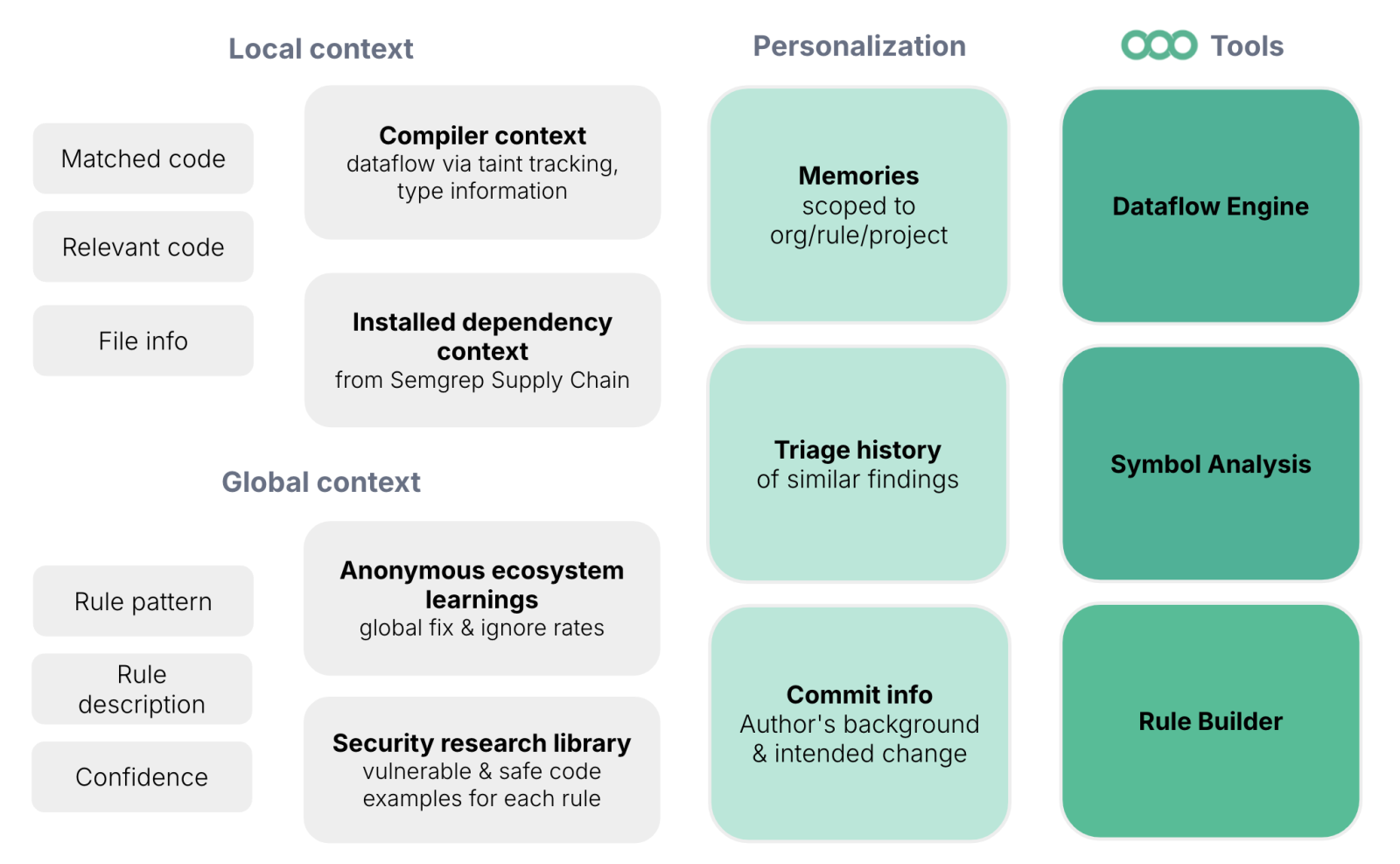
This diagram is high level and doesn't detail how we structure tasks for the model (items are not in any particular order).
Usability as the constant
Assume a skilled security engineer triages findings at ~95% accuracy. An agent that can match this rate will feel indispensable, but drop to even 85% and it quickly approaches unusable. Beyond the context and tools we pass to the model, the way we designed the autotriage system also plays a key role in the accuracy of Assistant. In short, Assistant acts only when it can do so with "confidence" (sorry, the short version usually involves anthropomorphizing AI).
Deliberate Asymmetry: Picking One Side of the Problem
A binary classification problem like triage doesn’t necessarily make for a good LLM task:
Trust is brittle: Security is high stakes, so even a small number of misclassifications can turn a product that automates X task into a product that helps humans with X task.
Class imbalance matters: If most issues are FPs, your product can be “accurate” by just labeling everything as a FP, but that’s not useful.
Asymmetry of risk: Mislabeling a real vulnerability as a FP is much worse than leaving an FP untriaged.
With Assistant, we didn't just throw a model at the problem space of triage, even if it seems logical (two possible outcomes). A model that tries to perfectly classify every issue as a true positive (TP) or false positive (FP) ends up mediocre at both. The way we identify false positives and the way we evaluate and provide reasoning for true positives are actually separate prompt chains that are not zero sum. Assistant only has the ability to triage and take action in the former system, and serves as a helpful aid that surfaces useful information in the latter.
Scope is variable, accuracy is not
When GPT-5 dropped, our accuracy or correctness didn’t suddenly spike — instead, our users saw Assistant triaging a larger volume of false positives for them. Accuracy always remains at 95%+ so usability is never fluctuating. As Semgrep learns more context about a customer's local environments, as we improve the systems powering Assistant, and as models themselves improve, users see this translated into a higher % of triage work taken off their plates.
Memories + local context
One big thing we shipped this year was “Memories”, a retrieval system that allows LLMs to remember and reference discrete pieces of critical context embedded as natural language. For example:
“Foobar is an internal service fully controlled by Acme Corp.”
“When code calls util.ValidateProxyRequest, untrusted data is considered sanitized.”
These memories are automatically created based on triage notes and developer feedback. They are scoped to specific rules, vuln classes, and projects to prevent logic sprawl. With memories being automatically generated and deployed by customers (after manual approval), we saw another drastic improvement in noise reduction:
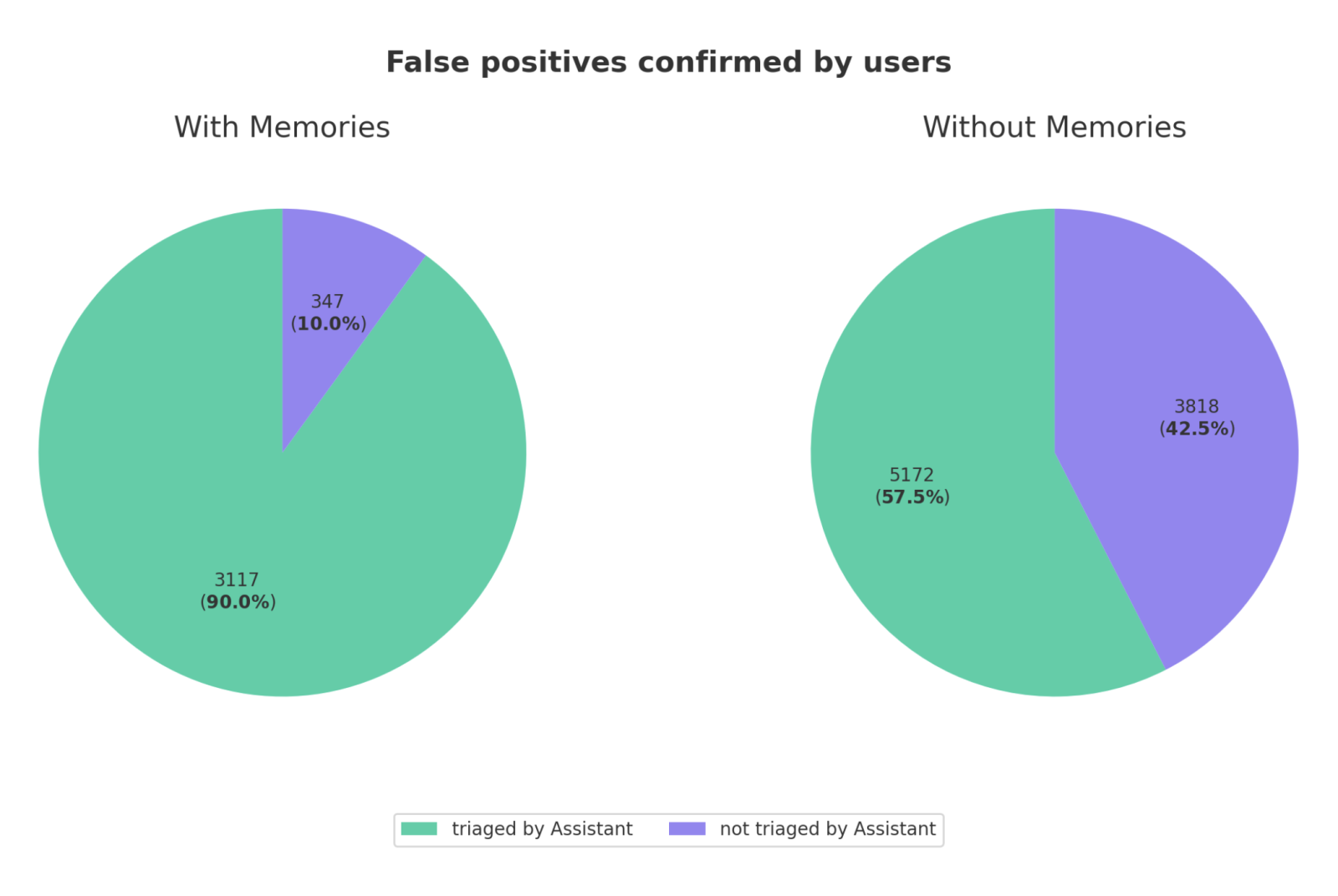
Looking at a dataset of total false positives (confirmed by users), we can see that memories give Assistant the context needed to take action on far more findings.
Conclusion: Same Model ≠ Same Accuracy
AI in security often feels like a demo — flashy, but too brittle to trust with real work. By deliberately scoping where it acts, grounding it in Semgrep’s detection engine, and giving it the local context it needs to make good decisions, we’ve built something rare: AI that security teams actually trust to handle a portion of their day-to-day work.
This isn’t about replacing security engineers, it’s about giving them back hours of time spent digging through layers of dataflow - just to find the smoking gun that makes a finding non-exploitable. And as models get better, developer and security feedback gets codified into Memories, and our systems keep improving, the percentage of work we can safely take off your plate will hopefully continue to climb.





