Secrets Story: The Prefixed Secrets That Tried%20to%2BGet\nAway
Examples of false negatives from real repositories leaked on GitHub and how secret scanning can be improved to find them.
Lewis Ardern
November 19th, 2025
To minimize false positives, secret scanning tools will make design choices with text matching to increase confidence. Our research found that these assumptions (specifically, non-word boundaries and keywords) cause them to miss valid live secrets. We share examples of false negatives from real repos leaked on GitHub, and how secret scanning can be improved to find them.
Secret scanning tools have become a must-have for application security teams, recognizing and reducing the number of leaked secrets like API keys, cryptowallets and other tokens. But current secret scanning tools often miss publicly leaked secrets due to over-reliance on false positive reduction techniques, letting the keys to the kingdom fall through the gaps in the floor boards. This blog post details how these methods, while intended to reduce noise, can lead to undetected valid secrets for a wide range of common tokens, including specific examples from GitHub, Gemini, OpenAI, Anthropic, and many more popular services. We provide recommendations for both secret scanners and third-party services to improve detection accuracy and prevent widespread accidental exposure.
In this post we review:
How secret scanners work.
How secret scanners reduce false positives using word boundaries and keywords.
Our experiment in scanning GitHub repos and finding missed secrets with examples for how services structure their secrets.
We conclude with recommendations for both secret scanning tools and third-party services to improve their secret management practices.
How Secret Scanners Work
Finding secrets usually requires detecting a specific keyword or prefix with some additional structure to identify common secret patterns. Most third-party services such as GitHub, AWS, Huggingface, OpenAI, Azure, etc. all have their own specific prefix. For example, Github Personal Access Tokens (PATs) are:
// classic tokens
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
// fine grained tokens
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
Some of the prefixes for Github are ghp_ and ghp_pat_ the rest of the content is the context of the token which would be found by the following regex:
Once something looks like a secret, scanners then generally send it to the respective service to be validated e.g. for GitHub you’d talk to their API to determine if it's valid or not based on the HTTP response e.g. 200 or 401.
Scanners look for additional keywords inside the file to reduce false positives, or enforce the secret is within a non-word boundary (\b) which ensures the secret is not within arbitrary long strings such as encoded and encrypted data, reducing false positives.
Optimizing for a low false positive rate can often have a consequence of a higher false negative rate. Deciding which to optimize for has pros and cons to consider.
How Secret Scanners Reduce False Positives
To develop rules that can identify and detect secrets with prefixes, the process has 2 stages:
Does this secret contain a unique prefix or unique identifier inside the secret?
Does this secret require additional false positive reductions to prevent sending secrets to the wrong third-party service or is it too generic and prone to false positives?
Let's look at the primary methods used to reduce false positives in secrets detection, where we are trying to avoid service overlap, or reduce the noise a finding might create.
Prefix Collisions and Lack of Uniqueness
Secret prefixes are not inherently unique to a single provider, this can lead to "prefix collisions," where a scanner might correctly identify a pattern but incorrectly attribute it to the wrong service:
sk_live_ is used by Stripe and APIDeck and use a similar token format, sk_test_ is common but usually differ in token format
sk- is used by both DeepSeek and legacy OpenAI secrets and have similar token formats
gsk_ used by Groq which can overlap with sk_ which has a similar format to other tokens
Prefixes can capture too many matches related to non-secrets or potentially other secrets, and scanners might attempt to validate a secret with an API that doesn't own it.
secret_ is used by Notion and ConvertAPI and could overlap with other services that contain the word secret_ somewhere within their token format
api- is used by LaunchDarkly but may overlap with Robinhood and other services that use api- somewhere within their token format
// Service one sk_live_
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
// Service two sk_live_
sk_live_Kt7AToMy6ZsvuD7FOLoHUbplyVqhO35NcRGlko0NITlCWKik9zKrKOaVRnpjtfCs1572OyoWfd4xZCaNpvZ9dZiD7-M9o
// Secret token format
api-b99a8586-630d-475f-ae89-79499d3223ec
// Arbitrary URL string matching secret token format
css-paint-api-1c99ed50-7d7d-43b4-bc1e-7f41684274ed
Some providers will add a unique value within the secret to help differentiate, such as newer OpenAI tokens start with sk- and contain T3BlbkFJ, so it's fairly simple to detect these types of tokens without any issues, however this is rare and limited to just a few services.
// OpenAI token with T3BlbkFJ
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
To combat this issue, secret scanners tend to use the following approaches to reduce false positives, by:
Enforce non word boundaries which can help differentiate between long strings of random letters and numbers and individual secret strings
Use keywords, looking for additional context around the secrets such as references to specific services.
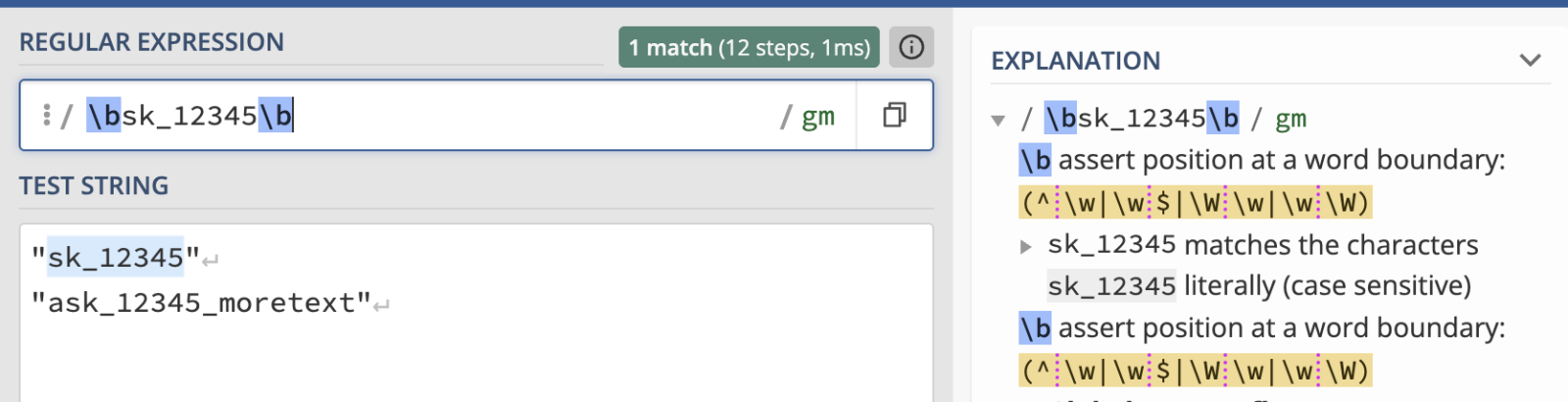
Word boundaries
Word boundaries (\b) are regex assertions that match the position between a word character (alphanumeric and underscore) and a non-word character, or at the beginning/end of a string. This is useful in secrets detection, as they are often used to ensure that a potential secret is not embedded within a larger string, which could be an encoded blob, an encrypted value, or just arbitrary text that coincidentally contains the secret pattern.
By enforcing word boundaries, scanners aim to reduce false positives by making sure the detected pattern stands alone, or is clearly delineated by non-word characters.
For example, a secret like sk_12345 might be detected within a string like randomtext_sk_12345_moretext without word boundaries. With word boundaries, \bsk_12345\b, the scanner would only detect sk_12345 if it was surrounded by non-word characters or was at the start/end of the line. This helps prevent irrelevant matches and reduces the number of non-secret findings.
In this example, ask_12345 is not matched because the a is a word, and \b enforces there must be a non-word boundary before the s and after the 5.
Keywords
Keywords can also play an important role in reducing false positives and directing potential secrets to the correct validation service. This reduction can be achieved in a couple of ways.
One common technique is to require a specific keyword before the detected secret pattern. This acts as a localized boundary, ensuring the secret is found within a relevant context. For example, a rule might look for deepseek followed by the regex sk-[a-z0-9]{32}. This helps prevent a random string that coincidentally matches the key pattern from being sent to a different provider if it's not explicitly labeled as a deepseek key.
This can also be at the file-level, where you may look for \bsk-[a-z0-9]{32}\b wrapped inside a boundary, but somewhere in the same file it needs to contain the word deepseek. Both approaches have their pros and cons, but are fairly effective at reducing the scope of false positives.
Scanning GitHub Repos and Finding Missed Secrets
During our research into word boundaries and keywords, we took common prefixed regex patterns that leveraged keywords/boundaries and we created permutations and searched GitHub to discover if there were valid secrets. Each query for every secret format was in the form of:
\Bsk-ant-api03-[\w\-]{93}AA\B
\Bsk-ant-api03-[\w\-]{93}AA\b
\bsk-ant-api03-[\w\-]{93}AA\B
\Bsk-ant-api03-[\w\-]{93}AA
sk-ant-api03-[\w\-]{93}AA\B
<repeat above with the word of service e.g. anthropic>
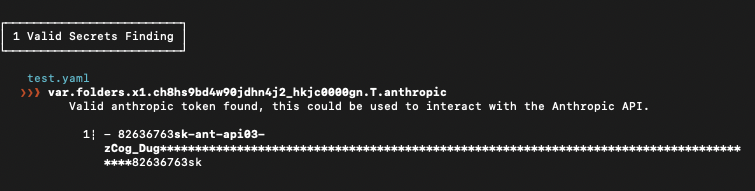
This allowed us to gather a variety of repositories which we then used Semgrep Secrets to discover if any of the findings were valid, and for any valid secrets we tested to see if other secret scanning tools would detect them.
Semgrep detected hundreds of valid secrets for various third-party services that are publicly leaked on Github. Despite the availability and popularity of secret scanning services, including GitHub, GitGuardian, Trufflehog, and Kingfisher due to false positive reductions such as non-word boundaries and keywords.
The main tokens discovered were GitHub classic and fine-grained PATs, in addition to AI services such as OpenAI, Anthropic, Gemini, Perplexity, Huggingface, xAI, and Langsmith. Less common but also discovered were email providers and developer platform keys.
We found that no provider we tested detected the valid tokens associated with GitHub.
GitHub secret scanning did not detect OpenAI tokens within word-boundaries, this includes push protection and once leaked within a repository.
The other tokens varied per-provider; some detected or missed Anthropic, Gemini, Perplexity, Huggingface, xAI, Deepseek and others.
The keys were missed due to either overly strict non-word boundaries or looking for specific keywords that either were in the wrong place or did not exist in the file.
Based on our research findings, Semgrep chose to adjust non-word boundary checks that we found to be unique enough to not require them. This helps ensure customers can achieve greater coverage without the tradeoff of increased false positives.
Problems with Non Word Boundaries
The use of non word boundaries can come at a cost, we observed secrets are leaked and not caught due to a number of reasons.
Intentionally or unintentionally within word-boundaries
Sometimes people accidently copy/paste secrets within word boundaries, we observed Github tokens with access to sensitive private repositories that were accidentally pasted within code/comment blocks e.g.
Terminal output, Newlines, ANSI, encoding and escape formats
Because non-word boundaries can’t have alphanumeric characters, common output or encoding formats will be treated like a word-boundary. Jupyter notebooks and patch diffs can include ANSI escape code that gets treated like a word boundary:
Decoded to "Bearer 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".
Non-word character end-lines and Binary and Caching output
If a secret tries to match something like \bprefix_[a-zA-Z0-9-]{10}\b if a secret ends with the non-word character “prefix_123456789-” because there is no transition from a word character to a non-word character at the boundary, you will lose findings. We found some secret scanners used boundaries and did not detect NVIDIA tokens that can end with a -.
The same is true for non-readable code and Python cache output:
WHERE id=?�Fr�Ynvapi-NLVahny7zYJWP46otFTq14bDR4pqlUZX0cSdnKjDMq8eq8Fc53Vi4KNd1FYMuP-C�a
Unnecessary boundaries
There are various cases where some secrets need to be wrapped in boundaries to prevent noise, however OpenAI has a unique identifier inside the string, so boundaries should not be necessary to detect this type of token. During our research we determined GitHub's secret scanning only detects OpenAI tokens when the surrounding content is a non-word character match, which was detected by the majority of the other secret scanning tools.
Boundaries are over-used and lead to false negatives. For example, the Anthropic token is unique and always ends with two AA letters. We determined most secret scanning tools will not detect non-word character matches for Anthropic tokens. This is also true for Supabase, Nvidia, Sentry, OpenAI, and a variety of services which have rather unique starting prefixes.
Generalized regex
GitHub has a variety of tokens which all communicate with the same API endpoints: this makes it desirable to create one regex to match all token types. It’s common to see secret scanners use a regex along the lines of:
This works well in practice, however it leads to a much larger false positive footprint than is necessary. ghp_ tokens are exactly 36 characters and they do not include an _, so including a range of 36,255 just means there is higher room for false positives. Due to this generalization, the use of word-boundaries is mandatory and means you will miss legitimate secrets. If scanners leveraged unique variations for each token type e.g. ghp[A-Za-z0-9]{36} this helps uncover more secrets while still keeping false positives fairly low.
Problems with Keywords
Similarly, keywords can be a big component in reducing false positives, however there are cases where the keyword used as a boundary will not detect the secret, for example if you look for the word deepseek and then the secret within a 0 to 40 character window of each other.
deepseek->0,40->\bsk-[a-f0-9]{32}\b
It’s common for people to leverage the OpenAI SDK to use Deepseek or other LLMs, and in cases like this, the secret will not be detected because the word deepseek is in the base_url, and not before the secret like the regex is expecting.
Developers will also use the wrong provider name when defining secrets, we observed people would call deepseek “OpenAI”, so even if you looked for the keyword within the file along-side the secret, you would fail to detect it due to the wrong provider name.
Without keywords for this type of prefix or a unique identifier somewhere inside the match, the chance of false positives increases or incorrectly identifies the service. This means secrets are left undetected as a tradeoff.
Recommendations for secret scanners
Periodically review your secret detection rules to see if they are too restrictive with keywords of non-word boundaries
You should write precise token formats for each version of a secret if they vary format lengths as generalizing can lead to false negatives
If SCMs provide push protection, they should have more rigorous checks once code is committed to help with secret detection
If a secret can contain - or other characters that would prevent non-word boundary matches at the end of the secret, add extra protections in detection and do not rely on non-word boundaries alone
Newlines, ANSI, encoding and escape formats may also be something to consider as a unique boundary definition when a secret is required to be within a non-word boundary
When reducing scope with keywords, determine if a keyword should be defined as:
Keyword boundary before the secret
Somewhere within the file or file name
Recommendations for third-party service providers
Document your exact token format and keep a historical record as they change/improve over time
Create a standard endpoint that can be used to verify tokens are valid
Try to use unique prefixes for your service to prevent product overlap chances e.g. ghp_ and github_pat_
If using a common prefix, add a unique identifier to prevent product overlap chances
Periodically review the regex sent to scanning services that have partner programs such as Github to ensure token formats are accurate
Consider a public revocation endpoint so people can help revoke leaked secrets, this comes at a double-edged sword since it may disrupt people's services if dependent on the leaked token
Monitoring public repositories for your own token types should be considered because not all secrets will be detected by the partner program, especially if the repo disables Github secrets protection or moves a repository from private to public
Enforcing tokens to have an expiration date, with fine-grained access will reduce impact against your service when tokens are leaked by your customers
Dive deeper into Security Research or continue reading our featured posts.


 Semgrep detected hundreds of valid secrets for various third-party services that are publicly leaked on Github. Despite the availability and popularity of secret scanning services, including GitHub, GitGuardian, Trufflehog, and Kingfisher due to false positive reductions such as non-word boundaries and keywords.
Semgrep detected hundreds of valid secrets for various third-party services that are publicly leaked on Github. Despite the availability and popularity of secret scanning services, including GitHub, GitGuardian, Trufflehog, and Kingfisher due to false positive reductions such as non-word boundaries and keywords.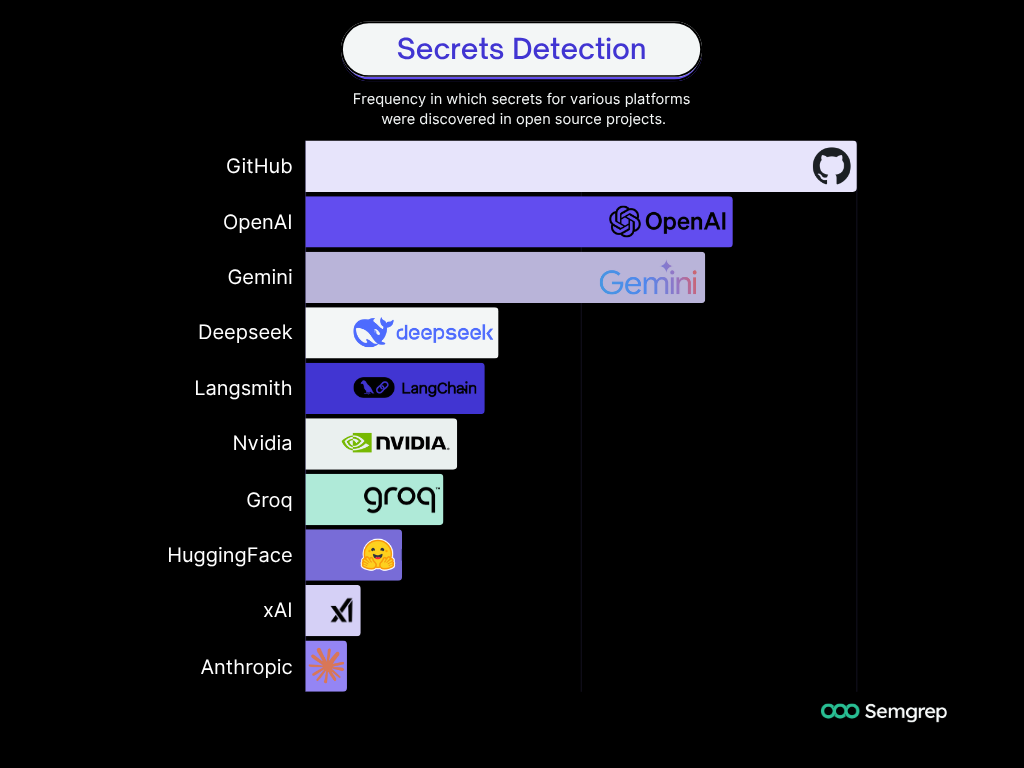 The main tokens discovered were GitHub classic and fine-grained PATs, in addition to AI services such as OpenAI, Anthropic, Gemini, Perplexity, Huggingface, xAI, and Langsmith. Less common but also discovered were email providers and developer platform keys.
The main tokens discovered were GitHub classic and fine-grained PATs, in addition to AI services such as OpenAI, Anthropic, Gemini, Perplexity, Huggingface, xAI, and Langsmith. Less common but also discovered were email providers and developer platform keys.

.jpg)
