We are excited to report that, as of 2025, Semgrep Assistant makes the same triage decisions for “true positives” as our own security researchers in 96% of cases.
Put another way: Assistant rarely misses a true positive, so security teams can confidently use Assistant to filter out non-exploitable findings (and tell developers that they will only be alerted when there are real issues with their code).
Reaching these numbers required a long journey (that is still ongoing!). We rigorously benchmarked Assistant’s triage decisions against those of our expert security research team, continuously refining the system to increase alignment between their judgments.
In this blog post, we’ll share how we achieved that benchmark, some of our learnings along the way, and where we are heading next.
How Assistant Autotriage Works
LLMs excel at reading code and interpreting intent, making them well-suited for evaluating security findings. Autotriage leverages this capability by using LLMs and retrieval augmented generation to assess the likelihood of any given Semgrep finding being a true or false positive. The result of an Autotriage is straightforward: a binary verdict of “likely true positive” or “likely false positive.”
To generate this verdict, we provide the model with the finding, relevant context, and detailed instructions on what to look for, asking it to evaluate exploitability just as an experienced AppSec expert would. In essence, we guide the AI to determine whether the finding is security-relevant or can be safely ignored.
The context we pass includes rule metadata, previous triage decisions on findings from that rule, examples of what the rule is supposed to detect or ignore, and any relevant Assistant Memories.
We also pass several dozen lines of code surrounding the finding in question to the model, alongside additional lines of code at each step of the finding’s data flow. This allows the LLM to get a fairly comprehensive understanding of what the code is doing, while also limiting how much code is passed to the LLM (for more on how we minimize the amount of data sent to and retained by AI partners, see our docs).
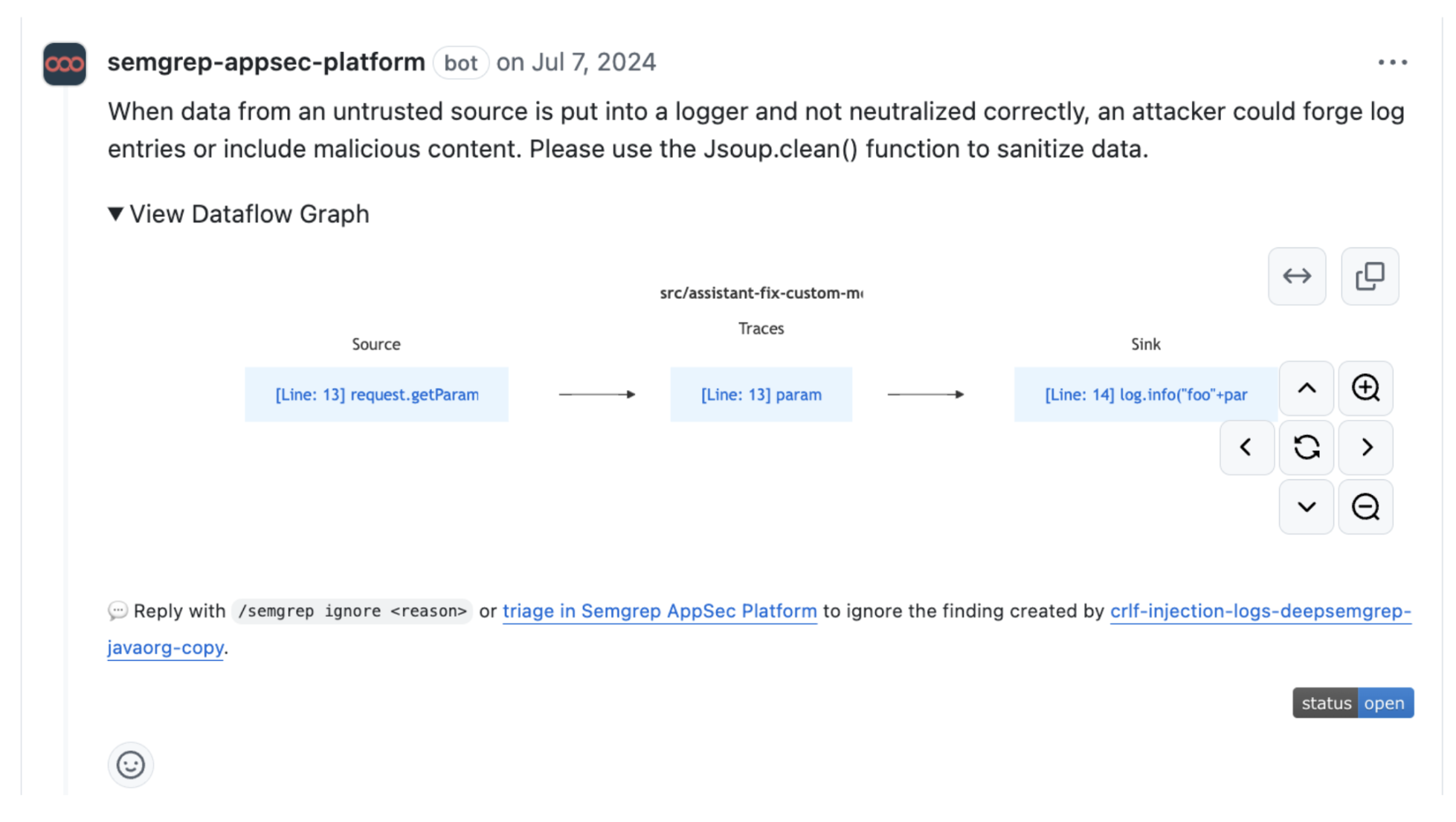
With this context, Assistant delivers a verdict of either “true positive” or “false positive,” along with its reasoning. If it identifies a true positive, Assistant generates a code fix and detailed remediation steps, sharing them as a PR comment and/or creating a Jira ticket. For findings deemed likely false positives, Assistant notifies the developer of the verdict and automatically tags the finding as a false positive in the AppSec platform, ensuring a streamlined and efficient workflow.
Tracking the Accuracy of Autotriage
When we launched Autotriage in 2023, we quickly began gathering user feedback. While the feedback was overwhelmingly positive, the volume we received wasn’t sufficient for our team to feel fully confident in Assistant’s accuracy. We were also concerned that our feedback collection method might be introducing bias. Since feedback relied on slash commands—a relatively high-friction interface—we worried that users who encountered disappointing results might simply move on without taking the time to provide input.
To gain a more comprehensive understanding of Autotriage's performance, we collaborated with our security research team to develop an evaluation set for benchmarking various models and approaches.
Our security researchers meticulously triaged a dataset of over 2,000 findings, classifying each as a false positive or true positive and providing detailed reasoning for their decisions.
Our internal benchmarks were run on the same dataset used by our security research team to improve and analyze Semgrep Code’s rule performance. This means that the set of findings used in this benchmark were designed to accurately model real world performance - comprehensive across languages, varying complexity, etc.
Once we compiled the dataset, we got to work using promptfoo to benchmark various models and settings, figuring out which of the many levers we could pull to improve accuracy.
Our initial results were surprising—Assistant agreed with security research triage decisions about ~55% of the time. This was disappointing, as our user feedback had indicated an agreement rate of over 90%.
Despite the challenges, we felt confident that we were moving toward greater rigor and had a clear understanding of how to improve the success rate based on our benchmarks.
Assistant Is More Conservative Than Our Security Research Team
The most interesting finding from our initial results was that, if we split out the triage decisions by verdict, we found a notable difference in performance.
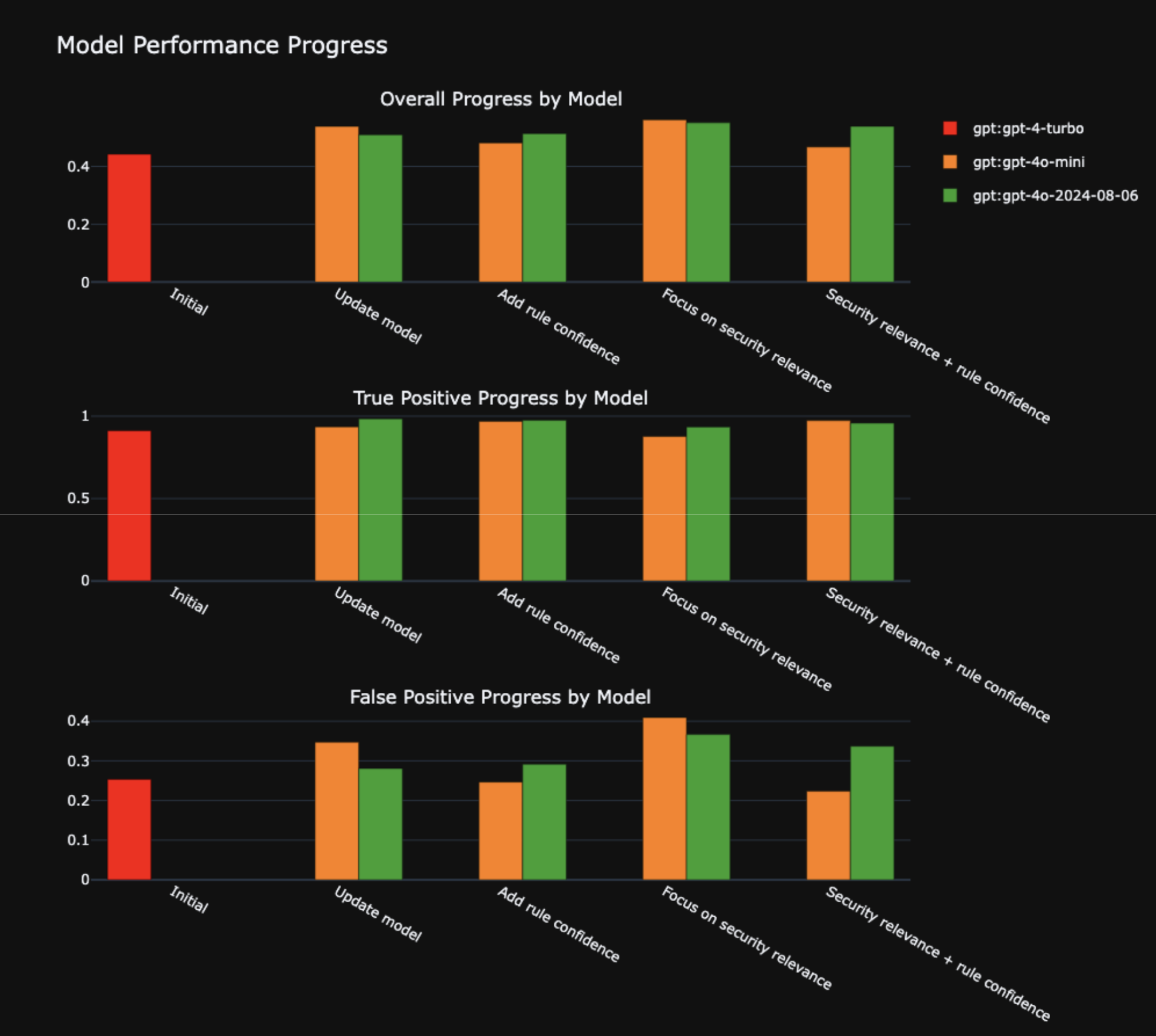
We discovered that Assistant was far more conservative than our security research team in identifying false positives. While our researchers often flagged findings as false positives, Assistant tended to err on the side of caution, rarely doing so. This discrepancy is likely due, in part, to the security research team’s ability to consider the full context of a project, whereas Assistant is limited to the dataflow trace it receives.
In our initial implementation, Assistant and the security research team agreed on true positive findings over 91% of the time but only agreed on false positives 25% of the time.
The encouraging news was that Assistant almost never missed a true positive—meaning it was highly unlikely for Assistant to tell a developer to ignore something our security research team would classify as a real issue.
The takeaway is that Assistant is highly proficient at catching true positives, but will occasionally recommend that users fix an issue that our security research team might deem safe to ignore.
Making Assistant Even More Accurate
While scoring in the low 90s for true positive detection was an impressive start, our ultimate goal was to make Assistant a truly agentic decision-maker. To achieve this, we set an ambitious target: over 95% agreement with the security research dataset on true positives. Importantly, we prioritized minimizing false negatives, ensuring that Assistant would rarely miss real security issues.
To meet this goal, we took several key steps:
Model Experimentation
We tested a variety of models, including gpt-4o, gpt-4o-mini, claude-3-5-sonnet, and others. Among these, gpt-4o delivered the best balance—achieving a high true positive detection rate while avoiding excessive conservatism in identifying false positives. As always, we continue to evaluate the latest models to ensure Assistant leverages the most effective model for each task.
Prompt Optimization and Contextual Enhancements
We refined Assistant’s prompts and experimented with adding more contextual information to improve its decision-making. By adopting the mindset of “what would someone triaging this issue consider?”, we identified additional bits of context that could enhance Assistant’s performance.
One standout example is the Semgrep rule confidence value. Set by our security research team, this value indicates how confident we are that a rule correctly identifies a true positive. Incorporating this information allowed Assistant to weigh findings more effectively—disagreeing more frequently with low-confidence rules while giving greater trust to high-confidence ones.
Balancing False Positives and False Negatives
This approach allowed us to reduce our false negative rate without compromising in our ability to accurately detect false positives (by far the most important criteria for Assistant to be useful to our users).
Through these efforts, we brought Assistant closer to achieving its goal of over 95% agreement with our security research team, making it an even more powerful tool for AppSec teams.
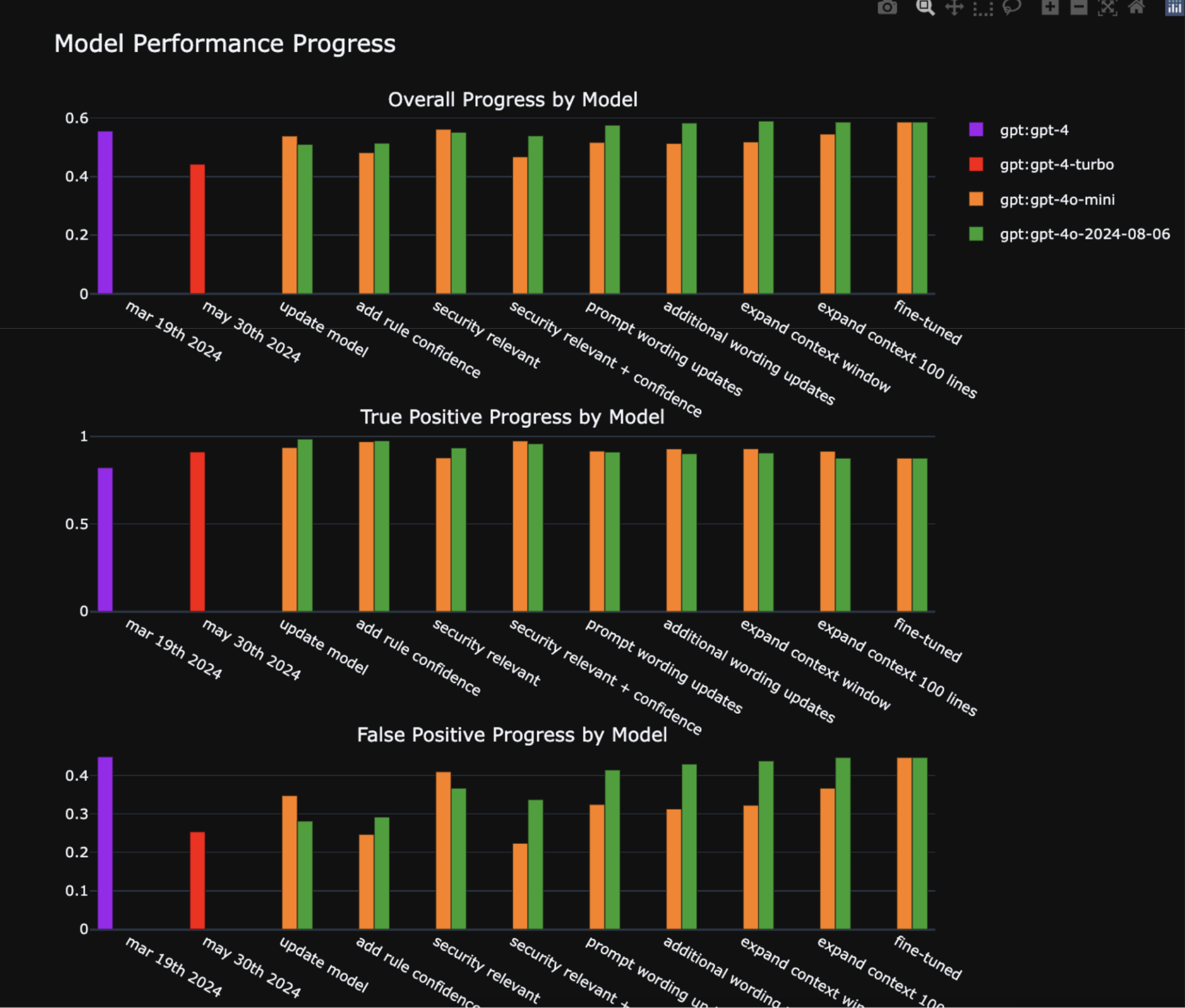
Interestingly, changes aimed at improving both true positive (TP) and false positive (FP) assessments often worked against each other. Enhancing Assistant’s ability to filter out noise led to a higher risk of missing important true positives. Given our long-term goal of enabling Assistant to take on autonomous decision-making, we made a deliberate design choice: optimize for minimizing false negatives, ensuring critical issues are not overlooked.
Ultimately, we achieved 96% accuracy on true positives exceeding our 95% goal. The agreement rate on false positives was 41%. Assistant is designed to be conservative—it’s more likely to suggest a developer fix a FP than ignore a TP.
Is 96% good enough?
It’s a fair question we’ve considered at length. While we’ll continue work to improve Assistant’s accuracy and expect models to improve, we think 96% good enough to use to inform decisions about what’s shown to developers and prioritized for review by AppSec Engineers. Why?
Reducing noise for developers is worth a few false negatives
The benefits of showing fewer FPs (filtered out by AI) to developers outweigh the cost of potentially not showing a few true positives. Showing developers fewer false positives overall means they’re more likely to fix the findings they do see, and less likely to tune out the system because it feels too noisy.
A high signal to noise ratio is critical for remediation
In any SAST program, maintaining a high signal-to-noise ratio is essential for driving remediation efforts—even if it comes at the cost of a few missed TPs. When the signal-to-noise ratio of a system falls below a certain threshold—even with just 10–30% noise—developers begin to tune it out. This phenomenon erodes trust and reduces the effectiveness of the entire program. By ensuring Assistant delivers high-quality, actionable findings, the net impact on security posture is overwhelmingly positive - developers fix far more issues, and fix them faster.
AI triage is better than no triage
While human security engineers can do a better job triaging, realistically, almost no AppSec teams have the time to triage all their findings. Many of our customers have backlogs with hundreds of thousands of findings. If a team with 100,000 findings in their backlog spent 15 minutes triaging every finding (a conservative estimate) it would take 3 humans working 24/7 round the clock for an entire year to complete the work - that’s assuming no new vulnerabilities are introduced.
Superhuman language and framework expertise
Even skilled human AppSec engineers often lack deep expertise in every programming language and framework used within their organization. Context-switching between languages and frameworks adds significant cognitive load, making consistent, accurate triage even harder. In contrast, AI can reference vast bodies of knowledge and handle findings from nearly any language or framework with ease, providing triage decisions that span the entire tech stack.
Our system allows AppSec to review Assistant’s decisions
Our system is designed to combine the strengths of AI and human review. Assistant determines whether findings should interrupt a developer’s workflow (e.g., whether or not to post a PR comment). This boosts developer velocity by focusing their attention on actionable findings and minimizing interruptions caused by noise.
Findings not surfaced to developers remain accessible in the backlog, allowing AppSec engineers to review all decisions. They can do this much faster than they normally would, since Assistant provides explanations for its decisions, and is correct over 95% of the time.
Moving Towards Agentic AI in AppSec
Achieving 96% accuracy on true positives marks a significant milestone on the journey to enabling AI to run parts of an AppSec program on autopilot. With this level of precision, Assistant can handle triage on your behalf—freeing you to focus on the critical work that can only be done with your security expertise and knowledge.
At this stage, Assistant doesn’t close findings; instead, it focuses on ensuring developers are only interrupted when confidence in a finding is high.
Even so, the impact is already substantial. By reducing unnecessary interruptions, Assistant is saving our customers tens of thousands of hours of developer time. This efficiency boost not only accelerates development but also improves security outcomes—developers are more likely to trust and act on security alerts when they see fewer false positives. As a result, we’re helping teams fix more issues than ever before, making shift left a reality, not just a buzzword.








.jpg)


