

Semgrep is used to scan source code. In fact, LOTS of code. Between Semgrep Community Edition and Semgrep Managed Scanning, Semgrep is used on everything from single file source listings to large monorepos and enterprises who have thousands of repositories.
For DevOps and system integration teams, the time it takes to complete a job is a priority. If development teams are stuck waiting for a build to finish, those teams will avoid running a scan which puts the organization at risk. Typical fork-join parallel processing is not new to Semgrep, but this has consequences for memory usage because program analysis requires maintaining state in memory. Left unchecked this has financial consequences on processing resources (ie. money on compute costs). Advances to Semgrep and the underlying implementation now allow us to take advantage of shared-memory parallelism known as Multicore OCaml.
The fall release of Semgrep Community Edition has added support for multicore, Windows, MCP, and much more. To help teams who are trying to scan source code to identify security vulnerabilities at scale, let’s look more closely at how multicore works.
What is Multicore?
Often, if you want to build or scan faster, you add parallelism. This can be done both through horizontal scaling (more machines) or vertical scaling (more cores, more threads). This approach doesn’t mean you are processing faster per se, it’s that you are doing more work in parallel.
Semgrep's traditional parallelism mechanism was process-based. When the process was forked into subprocesses, there may be some level of shared state through temporary files or other tricks but typically discrete memory heaps are created for each process. For a complex job like the program analysis that Semgrep does, this can create a bottleneck on the amount of system memory available as each process will have to duplicate the state.
Semgrep’s engine is written in OCaml in order to achieve these powerful static analysis capabilities. An approach for shared-memory parallelism called multicore was added in OCaml 5.0. This capability provides true concurrent parallel processing within the same process so multiple threads can safely access and modify data structures in common memory.
Adoption of multicore was initiated after we did an upgrade from OCaml 4 to OCaml 5 a few months back. As with most new capabilities in programming languages, for significant production use cases there are issues to resolve. This capability is important to get correct because it can make scans over large programs quicker while being more efficient in using compute resources.
Cost Implications for Inefficient Implementations
Typically, CPUs are cheaper than memory. A compute-optimized resource on AWS EC2 (C-series) compared to running the same job on a memory-optimized resource (such as R or X-series) can in some edge cases see nearly a 58% difference in cost for the same job.
What happens when you add parallel processing without considering the memory profile?
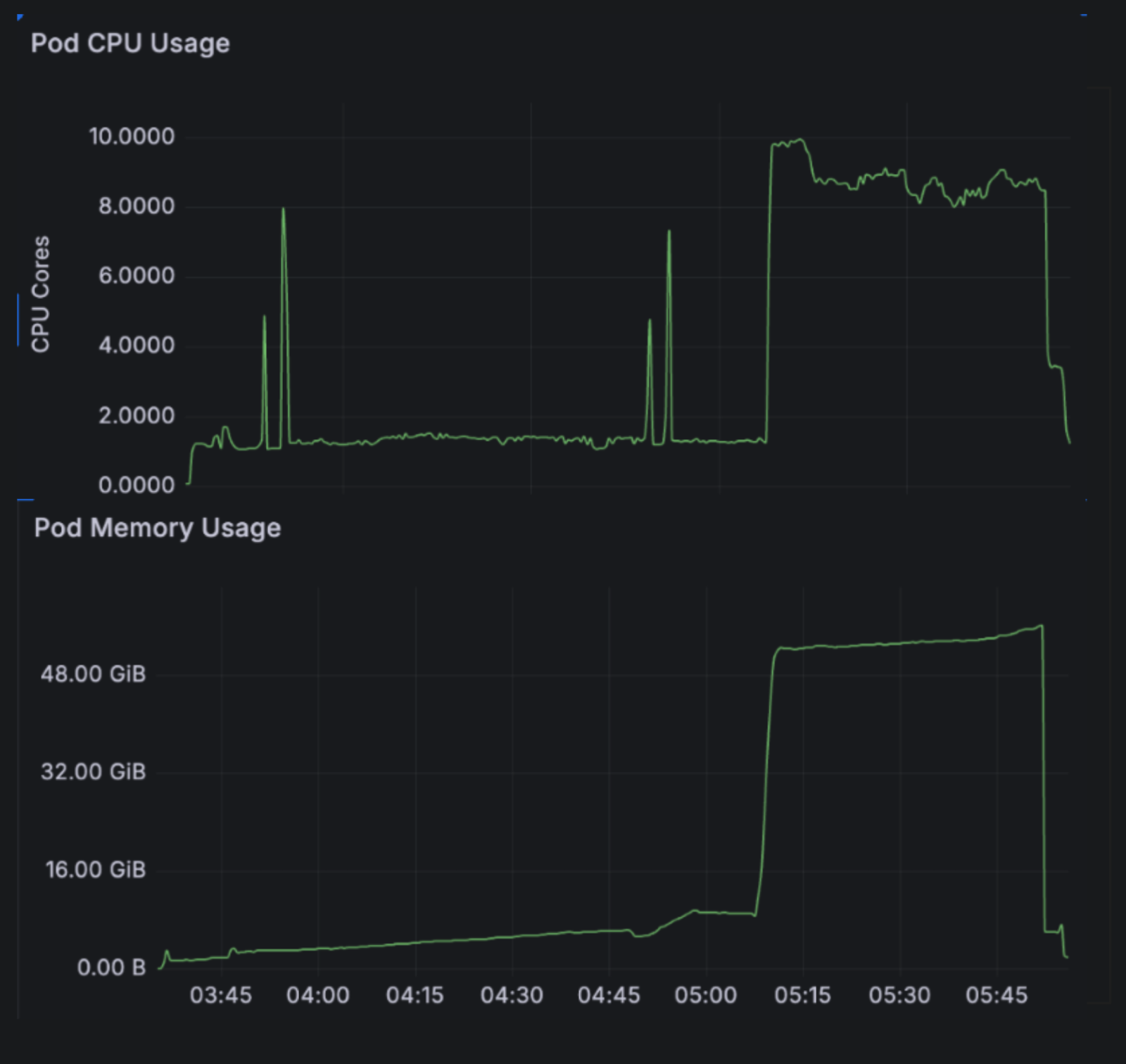 This Grafana chart shows CPU and memory utilization for a benchmark repository. With each distinct process, we add a new memory heap as the OCaml collector kicks in to induce a copy. The resident memory usage is directly proportional to the number of threads. For a deeper technical understanding, it is the impact of the garbage collector within each process that results in periodic big spikes and then a leveling off.
This Grafana chart shows CPU and memory utilization for a benchmark repository. With each distinct process, we add a new memory heap as the OCaml collector kicks in to induce a copy. The resident memory usage is directly proportional to the number of threads. For a deeper technical understanding, it is the impact of the garbage collector within each process that results in periodic big spikes and then a leveling off.
This is where OCaml’s latest multicore updates come in because managing memory efficiently can make a real difference. The core idea here is straightforward:
As we did before, we still split large codebases into independent chunks for processing.
Process those chunks in parallel across multiple threads with multicore.
In-process multi-threading now enables shared memory to be utilized across threads while using built-in methods to manage concurrency. This is not a trivial effort to ensure correctness with a shared memory heap when multiple threads each have read/write access.
The following graph shows the results on the benchmark repository for processing time and memory consumption across the different approaches
 The result (using secDevLabs as a benchmark) is that you don’t see the same linear spike in RAM usage that traditional process-level parallelism creates. Rather than consuming memory and thrashing the system when reaching eight cores, a much more defensible memory budget can be achieved while shrinking the time it takes to complete the job.
The result (using secDevLabs as a benchmark) is that you don’t see the same linear spike in RAM usage that traditional process-level parallelism creates. Rather than consuming memory and thrashing the system when reaching eight cores, a much more defensible memory budget can be achieved while shrinking the time it takes to complete the job.
As one of the first large codebases to use Multicore OCaml, our open source work was done in close collaboration with the OCaml compiler team to ensure performance and correctness.
Production Ready Semgrep Performance That Scales
We often look to customers for how best to achieve their performance goals. In some cases, this may be speeding up startup times in rule loading. For customers who run jobs at large scale, whether that is trunk-based development workflows that use a monorepos or platforms that run continuous integration scans we look for and address these performance bottlenecks through work like multicore.
Replit added Semgrep as their preferred security scanner, allowing vibe coders to use the Replit Agent to detect and immediately fix security vulnerabilities with the click of a button. Similarly, Gitlab integrates Semgrep as part of the GitLab SAST (Static Application Security Testing). Platforms like these that must continuously scan code, potentially seeing a 3X speed boost in scan time while preventing a corresponding memory rise can mean significant savings from this work.
Likewise, some enterprises use trunk-based development and need to scan large monorepos that have hundreds of individual contributors and thousands of source code listings. These use cases are what we had in mind when taking care to improve production performance.
Key Takeaways
For DevOps teams who are managing their own security scanning builds, multicore is not just about speed but efficiency. It is easy to check a box and fork a process to turn on parallel processing. Tuning for varied workloads with memory management is part of the magic that lets you do more with the same infrastructure, which directly translates into cost savings and quicker turnaround of jobs helps with development team happiness.
Faster builds/scans without upsizing VMs. Stay within the existing memory budget.
Better resource utilization. Use spare CPU cores on machines you may already be paying for.
Predictable scaling. Performance gains from multicore don’t need to come with unwelcome infrastructure costs.
Monorepos supported. Scan large codebases that might otherwise timeout or exceed memory allocation.
With the 1.143.0 and later releases of Semgrep, multicore is enabled by default. Update Semgrep to pull in the latest and start seeing more efficient scans. If you experience any surprising behavior, we want to know about it or the --x-parmap flag is added for backward compatibility. If you haven’t updated to the latest version, you can use the --x-eio flag to enable it.


.jpg)
