The tech behind Semgrep Assistant’s triage and remediation guidance
Semgrep Assistant is like having another median-level security engineer on your team, whose sole responsibility is parsing through findings and giving humans-in-the-loop (even those with no security knowledge) everything they need to quickly and confidently take the right course of action. How does it work?
Chushi Li
Rohit Jayaram
August 21st, 2024
When Assistant identifies a true positive, it gives users a detailed, step-by-step breakdown of how to remediate a finding, alongside a suggested code fix. Assistant can turn hours of researching a vulnerability and implementing a fix into 10 minutes of validating and spot-checking a generated code snippet.
How does Assistant work?
The short answer? AI and LLMs.
The long answer? Complicated prompt chains and evaluation loops that take in a variety of inputs, including project-specific data like dependencies and prior fixes, and even results from Semgrep’s deterministic static analysis engine. Much of our work developing Assistant revolves around improving the performance of these challenging prompt chains.
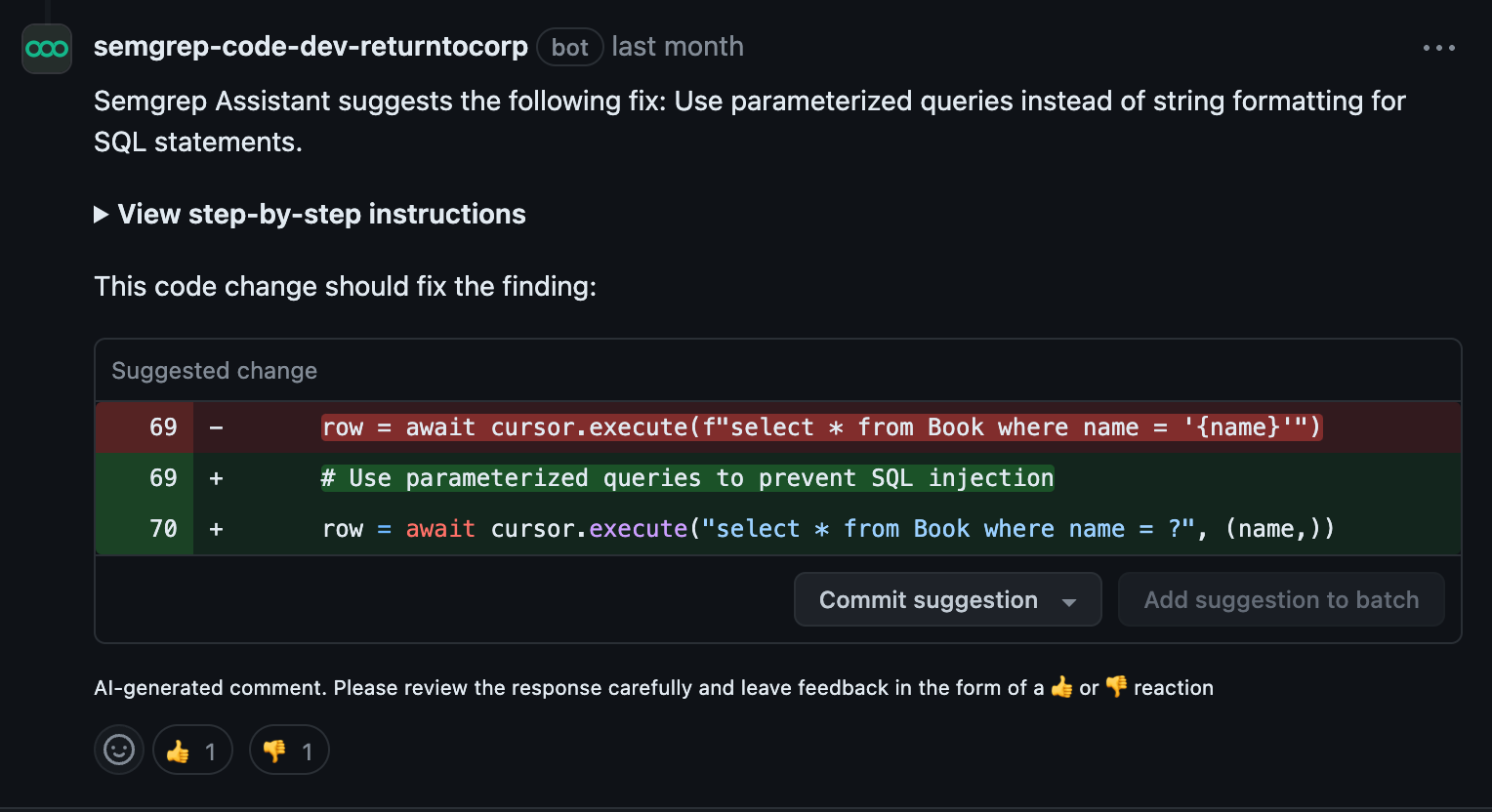
You may be familiar with the helpful PR/MR comments left by Assistant under the main Semgrep comment:
A PR comment left by Semgrep Assistant - fix guidance can be expanded by clicking "View step-by-step instructions"
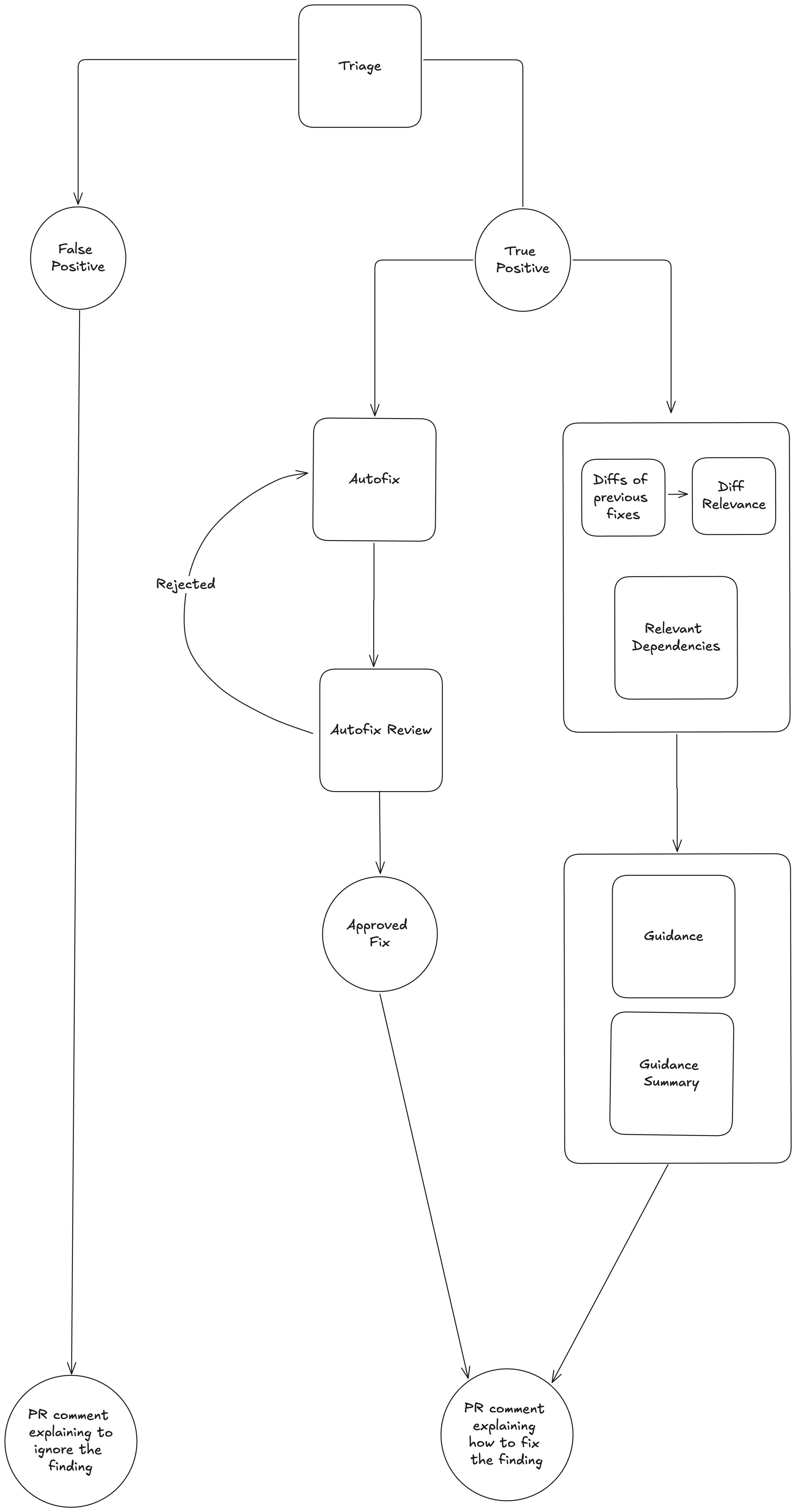
These PR comments are generated through a series of prompt chains which utilize complex information retrieval. Here is a simplified version of our existing infrastructure:
A simplified version of our prompt chain for Assistant triage and guidance
Feedback loops
You might notice in the diagram above that some parts of the generation process are in a feedback loop.
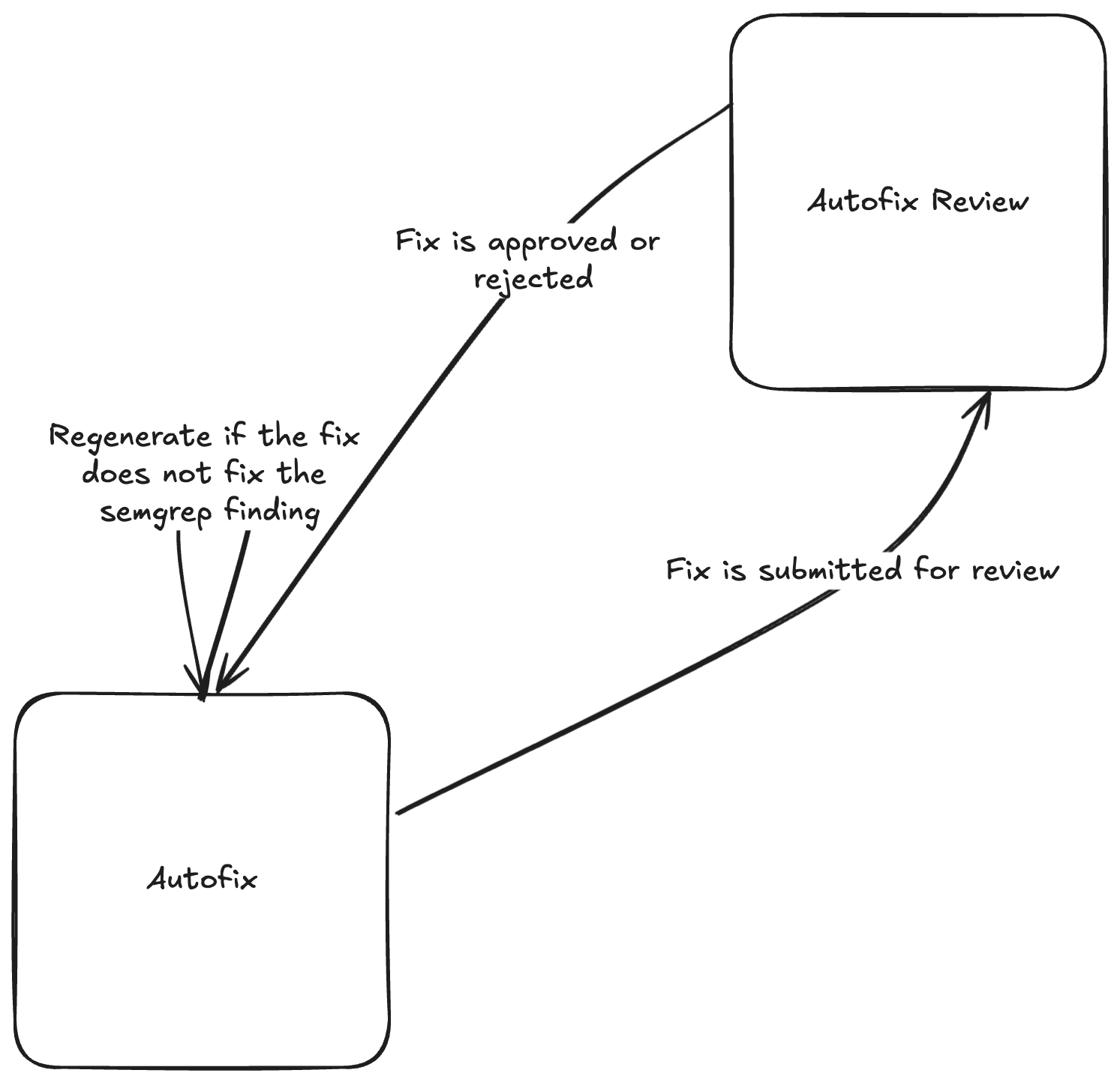
Let's look at the autofix section of the PR comment generation prompt chain:
The self-evaluation chain for Assistant's autofix
Here, a secondary review prompt chain is used to check both the validity of the Autofix and its ability to address the Semgrep finding. This chain rates the Autofix on the following attributes:
Whether the issue is still present
Whether there is malformed code
Whether more code or infrastructure changes are needed
Whether the LLM can even fix the issue
You might be thinking that the situation resembles this meme:
The analysis seems counterintuitive since we are using the same model to review its own output, but it actually works surprisingly well. We can think of the self-evaluation chain as "another human" in the loop since it is a completely different chain of thought. Don’t just take our word for it — research shows that self-evaluation improves model outputs on a fixed set of tasks.
We also use objective measures of outputs to determine the quality of responses. For example, the Semgrep engine verifies responses in several of our prompt chains. One notable example is the Autofix prompt chain, which evaluates its own result by running the generated code through the Semgrep engine to check if the finding has been resolved.
The advantage of this feedback loop method is that the engine captures a match’s exact location, which becomes additional context to feed back into the conversation with the model. This kind of back and forth with strict and loose verification methods produces high quality results.
This is all talk though - let’s see how it’s implemented! I find it to be an extraordinarily elegant usage of the python error system.
We return errors corresponding to the type of error strict (fatal) or loose (non-fatal):
raise AiFatalResponseParseError(
f"Could not successfully sanitize fix response {response=}. This is either due to empty input code, or the output response not being correctly formatted"
)
These errors are then caught inside the calling base class which handles the exceptions by appending the message to the chat:
except AiError as e:
messages.append(
OpenAiMessage(
role="system",
content=(f"The automated system trying to parse your response failed with the following error message:\n\n{e.message}\n\nPlease re-generate your response with the same instructions as before, but avoiding causing the same error."),
name="error_explanation",
)
)
But this is a fairly simple feedback loop since the only interesting change that we made is using the error messages in the conversation with the LLM.
The elegance comes when we declare a loose error. This is an example from our rule generation feature where we generate whole rules for you based on a description and some tests:
raise AiNonFatalResponseParseError(
f"Rule matched the good code that it should not have matched against. Keep in mind the intention of the rule. Rewrite the code based on the matches supplied in this json {results}.",
result
)
If we never succeed with generating a solution that passes all of the tests we raise an ExceptionGroup which allows us to parse through the caught exceptions and select a valid response even though it might not be ideal:
try:
...
raise ExceptionGroup(
f"Reached {unit_len(errors, "attempt")}, will stop trying to get a parseable response from GPT. All errors are fatal.",
errors,
) from e
except* AiNonFatalResponseParseError as e:
if isinstance(e.exceptions[-1], AiNonFatalResponseParseError):
result = e.exxceptions[-1].response
Retrieval Augmented Generation (RAG)
The Guidance Chain (as depicted in Figure 1) is one our most advanced chains when it comes to RAG.
It collects the following information before running:
Mitigations if there are any from the OWASP documentation
Any relevant dependencies that we are aware of from the finding’s project
Any previous fixes that we were committed that we know to have resolved a similar issue in the past
These insightful pieces of data are retrieved through these methods:
Vector Database
In Assistant, we frequently use our vector database to pull in static (or near static) information. This can range from information about rule patterns to documentation on the analysis of different chains. In the guidance chain, we use the latest OWASP documentation because it provides relevant information for addressing many Semgrep findings. We set a minimum similarity threshold that must be met for these entries to be included in our prompt.
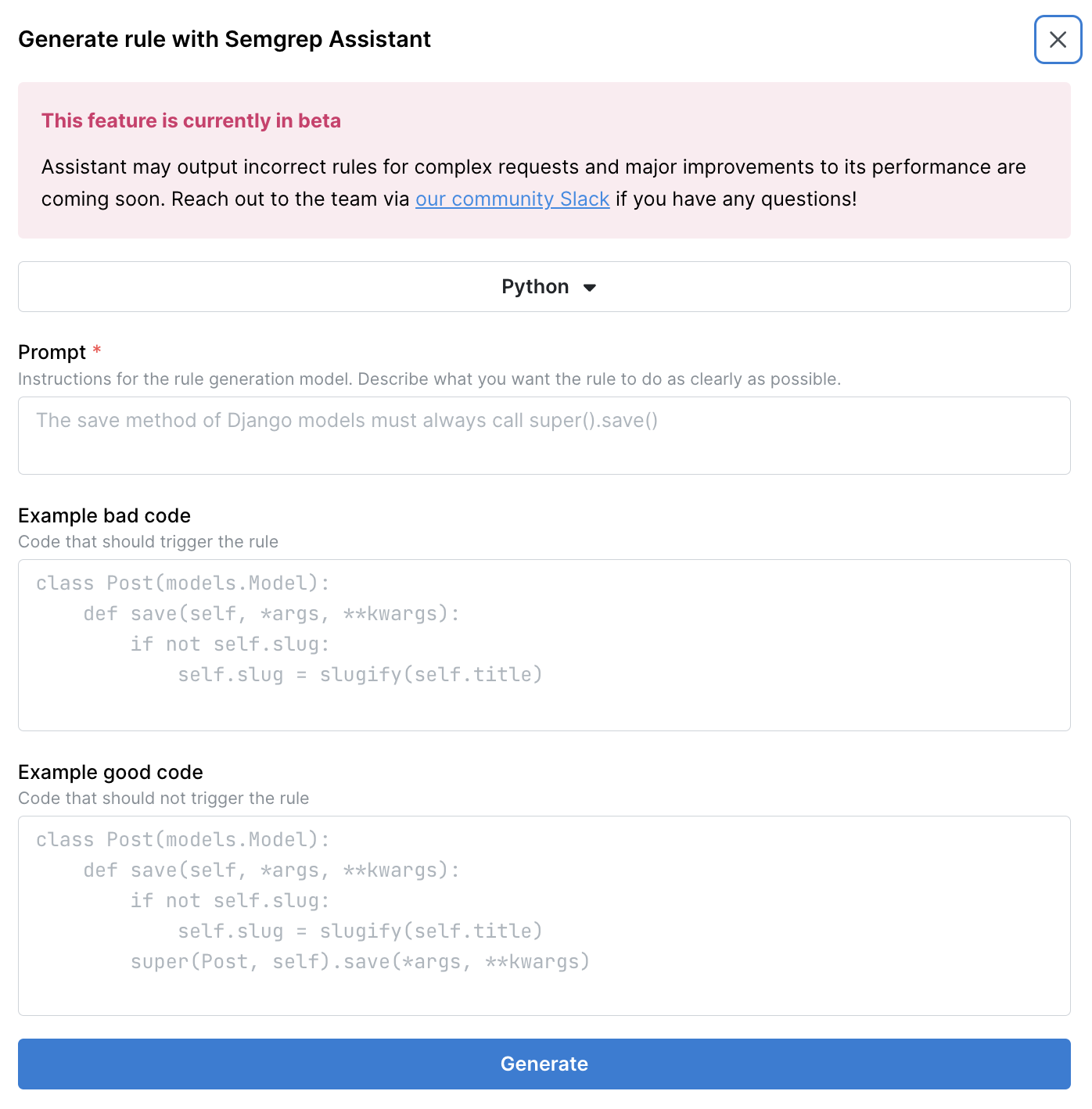
The most concrete example of the vector database improving performance is Semgrep’s rule generation feature. In this feature we attempt to generate a full rule based on a user description, some code that represents some of the correct implementations and code that represents some of the incorrect implementations.
For this feature we use embeddings of the rule message, patterns and language to improve the performance of the generation. We can see that this significantly improves the consistency of the generated rule passing Semgrep validation based on production data and our internal benchmarks.
How Assistant tailors results to a specific project
At Semgrep, we maintain a significant amount of technical data regarding a particular repository – what dependencies a project has, how a Semgrep finding was fixed, or what call paths in a project are vulnerable in relation to a particular finding. We even have the ability to generate graph structure files that describe the interlinking of functions and variables, similar to a SCIP file. So it make sense that we should use these insights to customize a project better to a particular project or organization. We do this throughout our chains in many varied and intelligent ways. But I want to highlight a couple of them that are particularly insightful and interesting.
Remediation Guidance Dependencies
In the remediation guidance prompt chain, we utilize the known dependencies and versions of those dependencies that are installed in a project to figure out what particular function or method to suggest as remediation. We also filter the dependencies that we present to the main guidance generation chain based on the relevance to the particular finding. We do this with another prompt chain so that we can stay targeted to the context of the current finding.
Previous Fixes
Similarly, we use our passive knowledge of what commits resolved a finding to retrieve the diff of that commit versus the commit that introduced the finding. This diff is sometimes large so we use another prompt chain to filter the diff down to only its most relevant elements, based on the rule and its intention. This method in particular has been shown to produce consistent guidance that is high confidence since the solution is something that has already been implemented by other engineers working on the repository.
Dataflow Traces
Any rule that has taint mode enabled gives dataflow info about how the finding was created. In the guidance and autofix prompt chains, we can use this information to give the models more context as to what could possibly fix the problems. This would result in guidance being able to reference specific files and locations in the provided tree also instead of guessing as to the location of calls to functions.




 For this feature we use embeddings of the rule message, patterns and language to improve the performance of the generation. We can see that this significantly improves the consistency of the generated rule passing Semgrep validation based on production data and our internal benchmarks.
For this feature we use embeddings of the rule message, patterns and language to improve the performance of the generation. We can see that this significantly improves the consistency of the generated rule passing Semgrep validation based on production data and our internal benchmarks. 

.jpg)
