





If you’re a regular reader of this blog, you may know that Semgrep is a fast, developer-friendly, customizable platform for securing your code. (And if you are not, you should check it out) Of all those descriptors, I feel like the most important may be “fast”. Without speed, developers can’t integrate it into their CI pipelines for automated checks because it would slow them down too much. Customizing rules would be a drag without speed because of how long you would have to wait between iterations. Everything people love about Semgrep would be moot if it took hours to run.
 So, we take Semgrep’s performance seriously. We’ve written before about how we make Semgrep so fast while remaining so powerful. By picking our battles, choosing our language well, taking advantage of the specifics of the problem we solve, and making useful optimizations, we’ve created one of the fastest static analysis engines around. And we mean to keep it that way. When we add new features (such as when we added the taint analysis mode), we iterate on them until the performance impact is small. When we notice anti-patterns causing specific rules to run more slowly, we make engine optimizations targeted towards those patterns. We have benchmarks that run on every commit to warn us of potential slowdowns, and we test particularly powerful features on a more intensive benchmark.
So, we take Semgrep’s performance seriously. We’ve written before about how we make Semgrep so fast while remaining so powerful. By picking our battles, choosing our language well, taking advantage of the specifics of the problem we solve, and making useful optimizations, we’ve created one of the fastest static analysis engines around. And we mean to keep it that way. When we add new features (such as when we added the taint analysis mode), we iterate on them until the performance impact is small. When we notice anti-patterns causing specific rules to run more slowly, we make engine optimizations targeted towards those patterns. We have benchmarks that run on every commit to warn us of potential slowdowns, and we test particularly powerful features on a more intensive benchmark.
You, the user, will always be the ultimate judge, but from what we’re seeing, we’re happy to say that our work has paid off. Even as our rules have increased in number and complexity, our average CI scan time for OSS scans has stayed the same—just under 10 seconds!
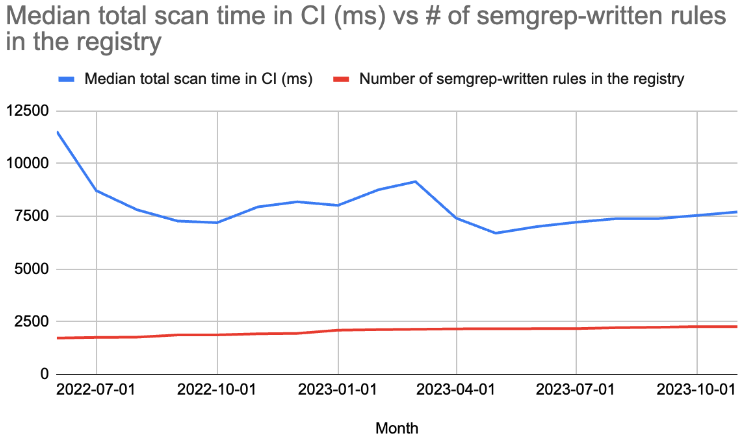 One distinction we should make: in CI, we can really speed things up by only scanning the files that were actually changed. Sometimes, though, you still want to do full scans. And those should be fast as well. For full scans, our average time for scans using the OSS engine is around 20 seconds.
One distinction we should make: in CI, we can really speed things up by only scanning the files that were actually changed. Sometimes, though, you still want to do full scans. And those should be fast as well. For full scans, our average time for scans using the OSS engine is around 20 seconds.
And, if you’re serious about using Semgrep for your security program, you probably want to perform a nightly pass on your code using our Pro Engine, which provides even more powerful analysis at the cost of some time. For full scans with the pro engine, the average scan time is under 300 seconds— much slower but still within the time you’d expect from a CI job. We’re committed to getting this number down, especially for large repos.
 Semgrep is never the blocker in CI process
Semgrep is never the blocker in CI process
Semgrep will continue to get more powerful, but we also intend for it to continue getting faster. We want you to be able to write a rule and scan not just your repo—not just your monorepo—but all of your repos, all the open source repos you’re interested in, and see if you find anything. We want you to write code in your editor of choice and have vulnerabilities flagged as soon as you type the last character. Because we know that for you to write great, safe code, security needs to be cheap, and time is one of the most expensive commodities around.
See how Semgrep enables Policygenius to shift left.
If you have not tried Semgrep yet, you can try it for free!


