

We’re excited to launch Semgrep Secrets, our secrets detection and remediation product that enables security teams to detect sensitive credentials in code that other solutions miss while integrating directly within the developer workflows. Semgrep Secrets is an addition to the product suite of Semgrep Code (SAST) and Semgrep Supply Chain (SCA), both of which are powered by the Semgrep Cloud Platform, which guarantees consistently high-quality findings.
The credentials to an organization's systems and data are prime targets for malicious actors. The repercussions of such keys falling into the wrong hands are severe—massive data leaks, unauthorized access to sensitive systems, and damage to the organization's reputation.
Secrets detection using Semantic Analysis
Unlike any other secrets scanner, Semgrep Secrets can reason about how data is used within your code. Traditional scanners are limited by regex capabilities and can’t leverage any form of data-flow analysis for detecting secrets which results in a lack of prioritization of results and missed coverage. Let’s look at a couple of examples to understand how Semantic Analysis works.
In this first example, Semgrep detects the hardcoded credential on Line 8. This credential is likely to get picked up by most scanners as the word ‘password’ is a common keyword regex scanners look for.
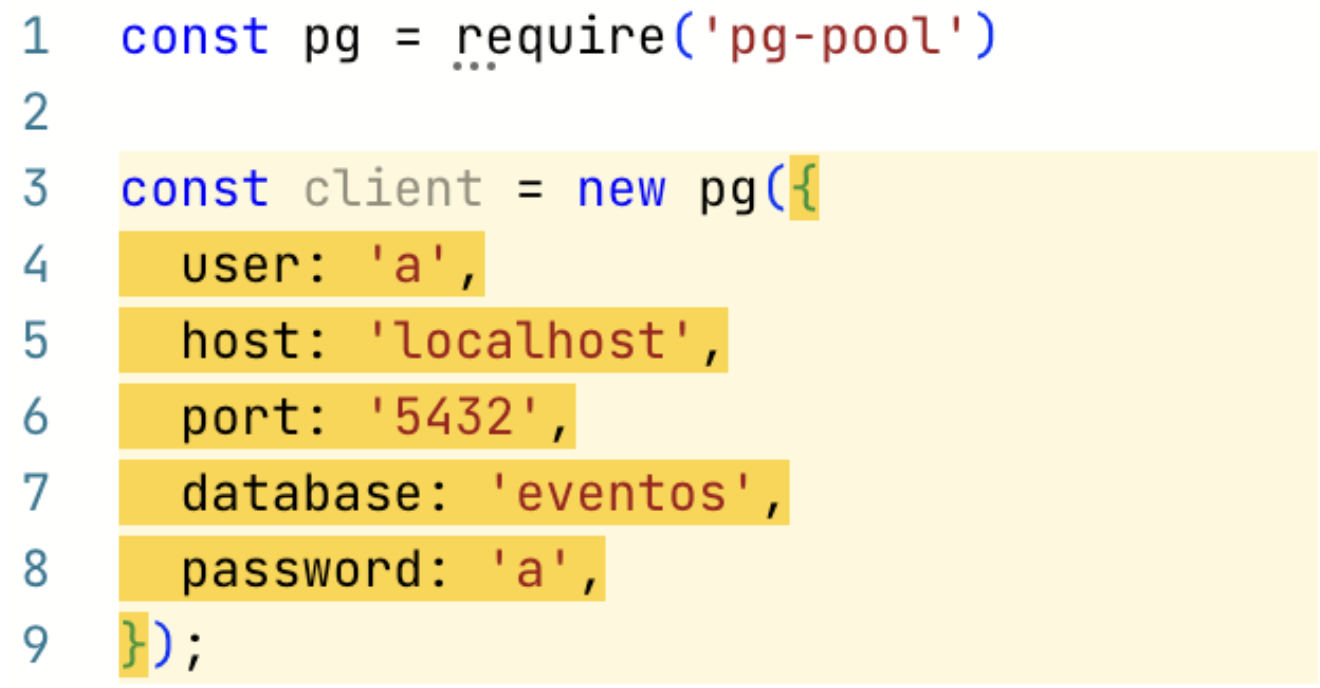 Example 1 of Semantic Analysis
Example 1 of Semantic Analysis
However, just detecting the word ‘password’ can result in quite a bit of noise; comments, random variable names, and test code are common areas where that keyword may be present but just the existence of the word ‘password’ does not mean a credential is present. The organizations we’ve spoken to ended up disabling these generic checks entirely because of the noise.
Semgrep can understand code context to help teams prioritize even these generic checks. In the above example, Semgrep knows that ‘pg-pool’ in Line 8 is a common Postgres connection library. Semgrep can convey that not only did it detect a hard-coded credential on Line 8 but that it is part of a database connection being created in Line 3. For security teams, hardcoded database credentials likely rank higher in the list of priorities, giving teams the flexibility to filter down to these specific results and even surface these findings directly in developer workflows as pull request comments.
The next example shows how Semgrep can understand not only how MongoDB connections are made but also track the flow of sensitive data into the DB connection.
 Example 2 of Semantic Analysis
Example 2 of Semantic Analysis
Semgrep rules indicate that the second parameter passed into the MongoDB connection strings are passwords. Once Semgrep extracts the second parameter on Line 10, it looks to see whether this variable is a hardcoded string. Semgrep determines that u.p is set to a hardcoded string and, therefore, flags Line 10 as a leaked secret. Line 13 is not flagged because Semgrep does not see env.password123 as a hardcoded string anywhere in the file (Semgrep is able to look across file boundaries with the Pro Engine).
The above example also highlights several shortcomings of regex-only scanners. Because the word “password” or something similarly generic is not used as a variable name, regex scanners are likely to skip Line 5, resulting in a potential false negative.
Validating if a secret is active
With Semgrep Secrets, we’ve built Semgrep’s first engine post-processor. We perform validity checks to confirm that the detected credentials are not just present but also active, allowing you to prioritize the most critical secrets. This saves you and your developers time by shifting the focus to mitigating the risks associated with live keys.

How does validation work
In the below example, Semgrep is able to identify GitHub PATs as they are uniquely prefixed with values such as ‘ghp’ or ‘gho’ as shown on Line 29. These tokens are then used to make a request to the GitHub API to determine whether they are still active. A ‘200’ response indicates the credential is still valid, whereas a ‘404’ indicates that the token is invalid. Lines 36-53 highlight the Semgrep post-processor definition within the rule itself.
 Validation of secrets
Validation of secrets
Building the validation post-processor into the Semgrep Engine has two main benefits:
First, validation occurs locally wherever Semgrep is running; Sensitive credentials don’t need to be sent to Semgrep’s servers to perform validation.
Second, organizations can modify or write their own validation checks. Teams that use a self-hosted version of GitHub may need to make a request to ‘xxx.api.github.com’ instead of ‘api.github.com’ which can be done by slightly modifying the above rule. Teams can also write their own validation rules from scratch to validate internal endpoints bespoke to their environment.
Entropy analysis
Entropy analysis measures how information is encoded in a string. We've made improvements to Semgrep OSS Engine's entropy analysis to provide more precise results. Let’s take the following example:
this.txtCfmPassword.Name = "txtCfmPassword"
In Semgrep OSS, this is flagged as a high entropy string, but Semgrep Secrets' entropy analysis correctly removes this match. There are many additional examples where Semgrep OSS will highlight similar false positives, which makes surfacing results to developers difficult due to the low signal-to-noise ratio. With Semgrep Secrets, we can reduce false positives so you and your developers can focus on the issues that matter.
Developer workflows
Like with Semgrep Code and Semgrep Supply Chain, the developer experience is a key focus for Semgrep Secrets. Developers love Semgrep pull request (PR) comments as they can get findings in real-time as they make changes and can interact with these findings all without leaving their SCM.
 Developers can fix security issues without leaving their workflow
Developers can fix security issues without leaving their workflow
Semgrep also supports running Secrets scans via pre-commit hooks to prevent secrets from even being committed.
Next steps
We are thrilled to announce the Public Beta of Semgrep Secrets as we expand our product suite further to provide complete build-time security to organizations around the world. Book a demo with our team to learn more.


.jpg)
