

tl;dr: Semgrep is a code search tool that many use for security scanning (SAST). We added GPT-4 to our cloud service to ask which Semgrep findings matter before we notify developers, and on our internal projects, it seemed to reason really well about this task. We also tried to have it automatically fix these findings, and its output is often correct. The first private beta invites are planned for April 6th—sign up for the waitlist
Auto-triaging findings with GPT-4
We tend to think of our features as either primarily loved by security teams or by developers. The Semgrep Code feature getting the most developer love is probably its pull request comments. It's weird, however, that even with our best foot forward, meeting devs where they like, we still sometimes see negative sentiment regarding our notifications. SAST industry-wide has a bad reputation of showing tiresome false positive alerts; in fact, various vendors are competing in the ballpark of 10-50% false positives[1-3].
When you are presented with many alerts, each one needs to be triaged for whether it is a true or false positive — requiring you to think deeply. When you triage an alert as a false positive, you’ll mark it as ignored and likely put your reasoning in writing. Less experienced developers find this process disproportionately difficult. A junior developer might struggle to imagine or understand what a Semgrep rule was even supposed to find, and be forced to send off an anxiety-ridden request for help with getting rid of the finding. In other cases, we see developers add ugly workarounds to 'fix' a false positive, not realizing it wasn't a real issue, to begin with.
The great thing about GPT-4 is: we don't need to write a whole section on the technical solution. The above problem statement is pretty much the solution itself! We can describe the problem, add around 3,000 tokens (about a thousand words) of context about the code, rule, and pull request, and it can respond with insightful triaging decisions.
Some of the false positives it can explain are inevitable with a tool that can 'only' pattern match code. For example, to a code parser, an accidentally committed real password is indistinguishable from a deliberate placeholder. GPT-4 however is able to recognize and reason about why such a finding is safe to ignore:
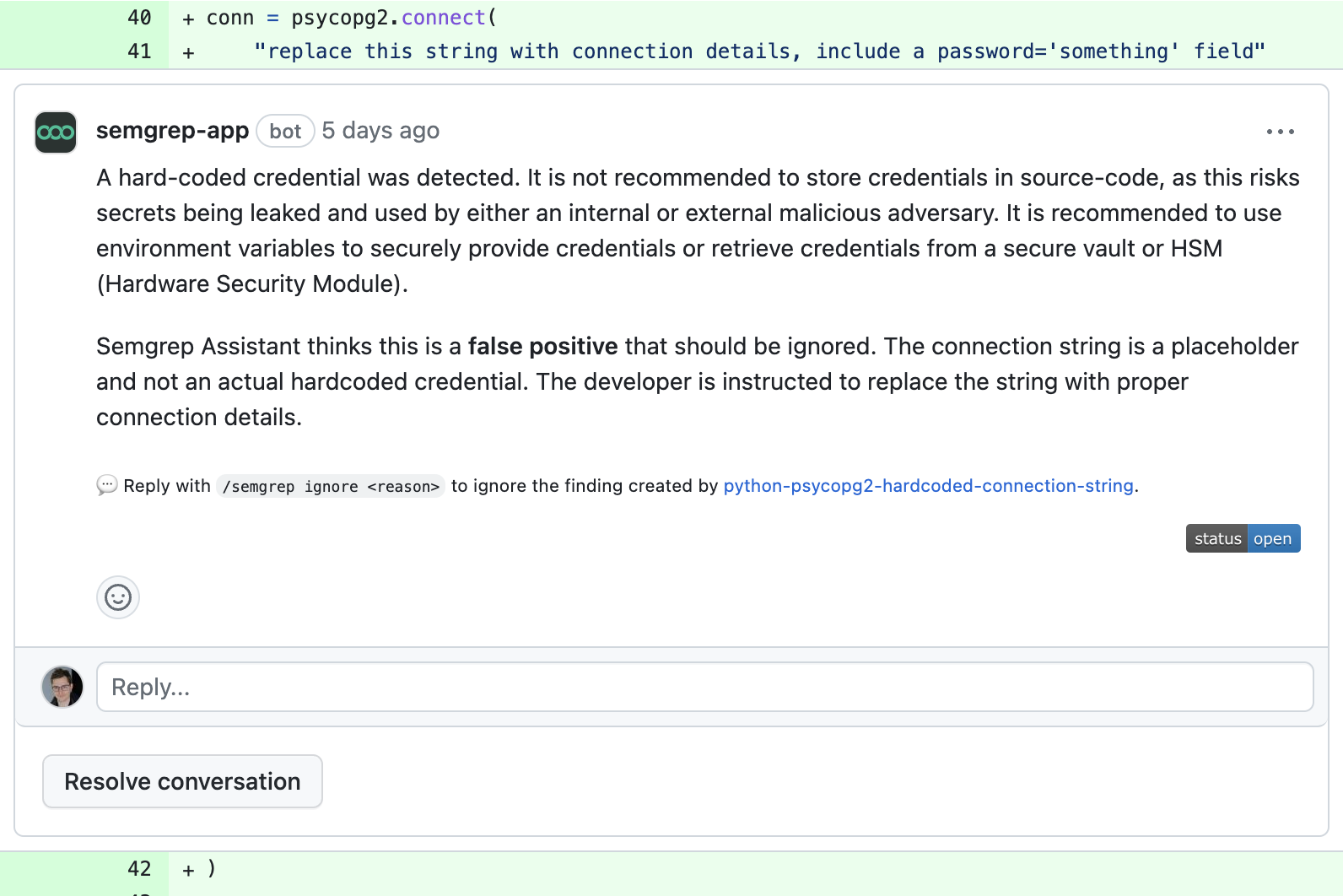 Other false positives come from rules that match too broadly. Official Semgrep Registry rules are tuned for precision and low false positive rates, but our users write a lot of custom internal rules too, and those rules don't go through the same tuning process. We have a lot of internal custom rules, primarily for coding standards. We tend to spend no more than five minutes writing and deploying one of these, and we definitely see a higher false positive rate on those.
Other false positives come from rules that match too broadly. Official Semgrep Registry rules are tuned for precision and low false positive rates, but our users write a lot of custom internal rules too, and those rules don't go through the same tuning process. We have a lot of internal custom rules, primarily for coding standards. We tend to spend no more than five minutes writing and deploying one of these, and we definitely see a higher false positive rate on those.
GPT-4 can use its understanding of programming languages and libraries to point out when a finding is just plain wrong and not applicable for a line of code. In the following example, we have an internal custom rule warning devs to use react-router's navigation instead of the browser navigating to switch from page to page. This would normally allow for proper, fast single-page app navigation. But the rule's author forgot to consider that react-router can only navigate to internal URLs on the Semgrep web app, while navigating to other domains is only possible by using the browser. This kind of false positive is particularly prone to confusing developers who themselves might not be familiar with this limitation. GPT-4 however does know, and leaves a useful explanation:
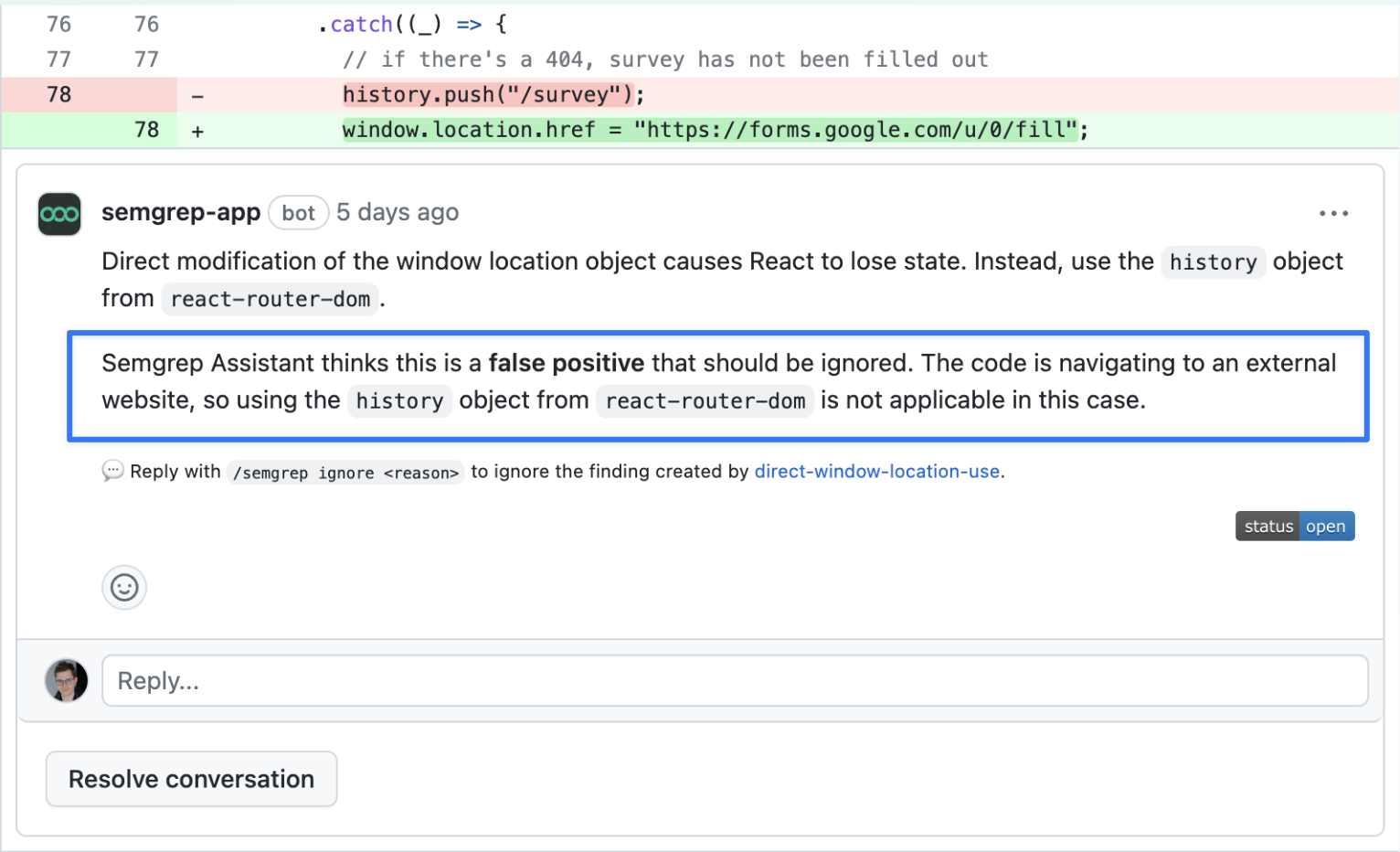 We found the AI to be impressive at triaging. This is also an ideal interface for AI suggestions that are, of course, still non-deterministic and ultimately unreliable. After all, what 'Semgrep Assistant thinks' is just a hint that ideally reveals some new information. It's like having a code reviewer who often makes helpful suggestions, but is sometimes wrong. All agency remains in the developer's hands, and a wrong one-liner AI assessment barely gets in the way.
We found the AI to be impressive at triaging. This is also an ideal interface for AI suggestions that are, of course, still non-deterministic and ultimately unreliable. After all, what 'Semgrep Assistant thinks' is just a hint that ideally reveals some new information. It's like having a code reviewer who often makes helpful suggestions, but is sometimes wrong. All agency remains in the developer's hands, and a wrong one-liner AI assessment barely gets in the way.
Auto-fixing code with GPT-4
A confirmed true positive finding means that there’s an issue in the code that should be fixed. To be upfront, our goal is that AI generated autofixes are directly committable 90+ percent of the time, and we are not there yet. On internal projects, AI fixes can be outright accepted ~40% of the time, and used as a good starting point another ~40% of the time.
The obvious challenge is figuring out how to prompt the AI to do the right thing, and we're still trying ideas to improve our performance here. We've experimented with chaining models: asking GPT-4 to assess the finding and also output a prompt for a purpose built code editing model, code-davinci-edit-001. In our testing, we saw it get distracted and make unrelated edits if we pass in too much code, and it often makes the wrong assumptions about context if we pass in too little. For now, we settled on using GPT-4 directly to make changes, which seems less likely to bump into either of these problems. If you have ideas on how to prompt our way around this predicament, please do reach out! (Slack / email / jobs)
Our existing users will recognize that we already have a similar autofix feature built into Semgrep as part of our rule syntax. And indeed, we don't see AI suggestions replacing hand-written precise and deterministic codemods anytime soon. It seems on the other hand that AI is capable of autofixing an entirely different set of issues well. See the below illustration of when AI knowledge comes in handy.
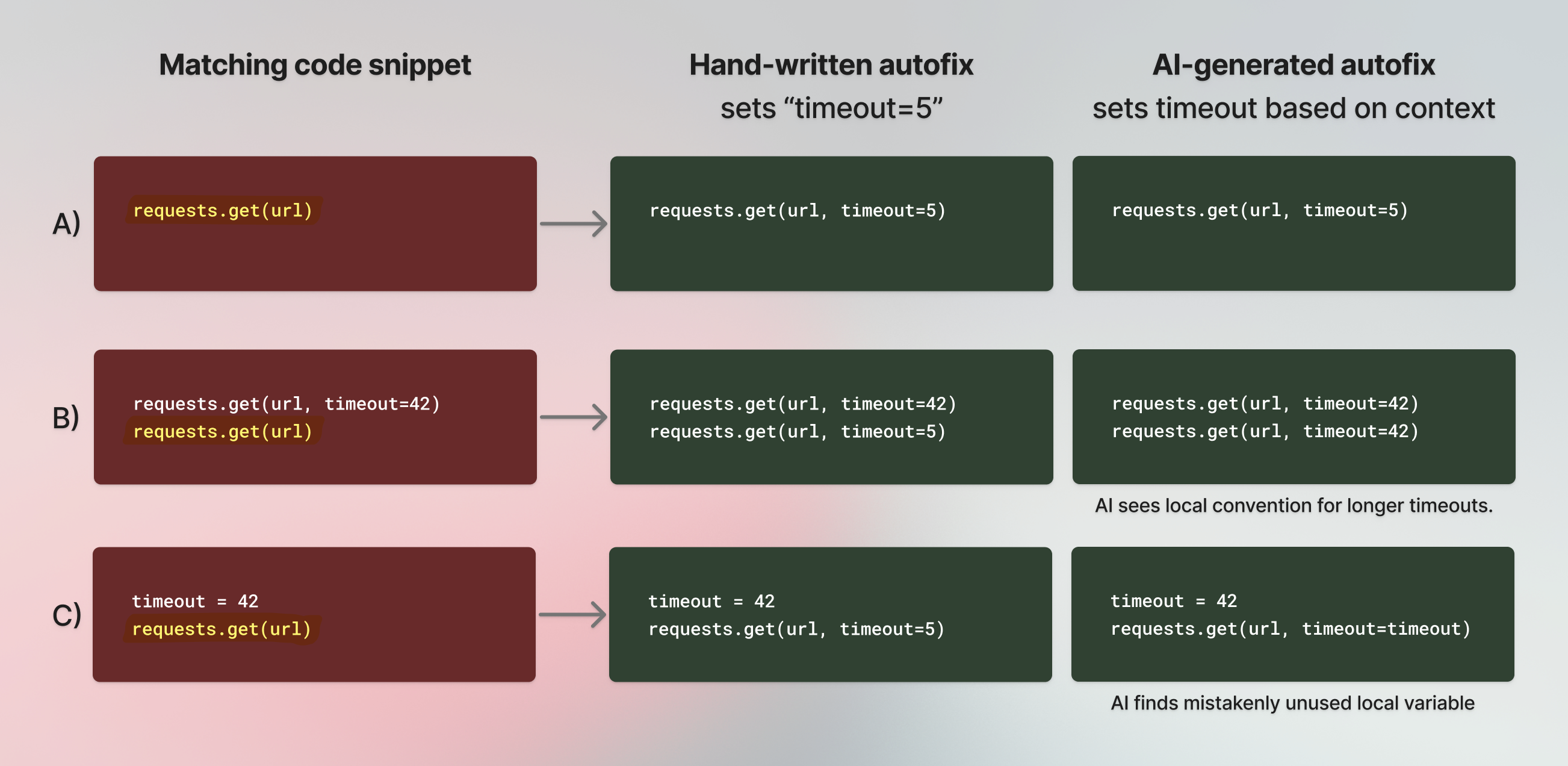 For this specific rule, the fix often depends on local context, which is not currently (and might never be) possible to express with a declarative autofix replacement pattern. Another example of what you probably won't ever be able to express in a rule definition are the fixes to some coding convention or even phrasing rules. One such rule we have internally that sees AI perform really well is our rule for log message conventions. Log messages must match a regex such that the message become easily indexable keywords, and GPT-4 can easily make traditional English messages match this format:
For this specific rule, the fix often depends on local context, which is not currently (and might never be) possible to express with a declarative autofix replacement pattern. Another example of what you probably won't ever be able to express in a rule definition are the fixes to some coding convention or even phrasing rules. One such rule we have internally that sees AI perform really well is our rule for log message conventions. Log messages must match a regex such that the message become easily indexable keywords, and GPT-4 can easily make traditional English messages match this format:
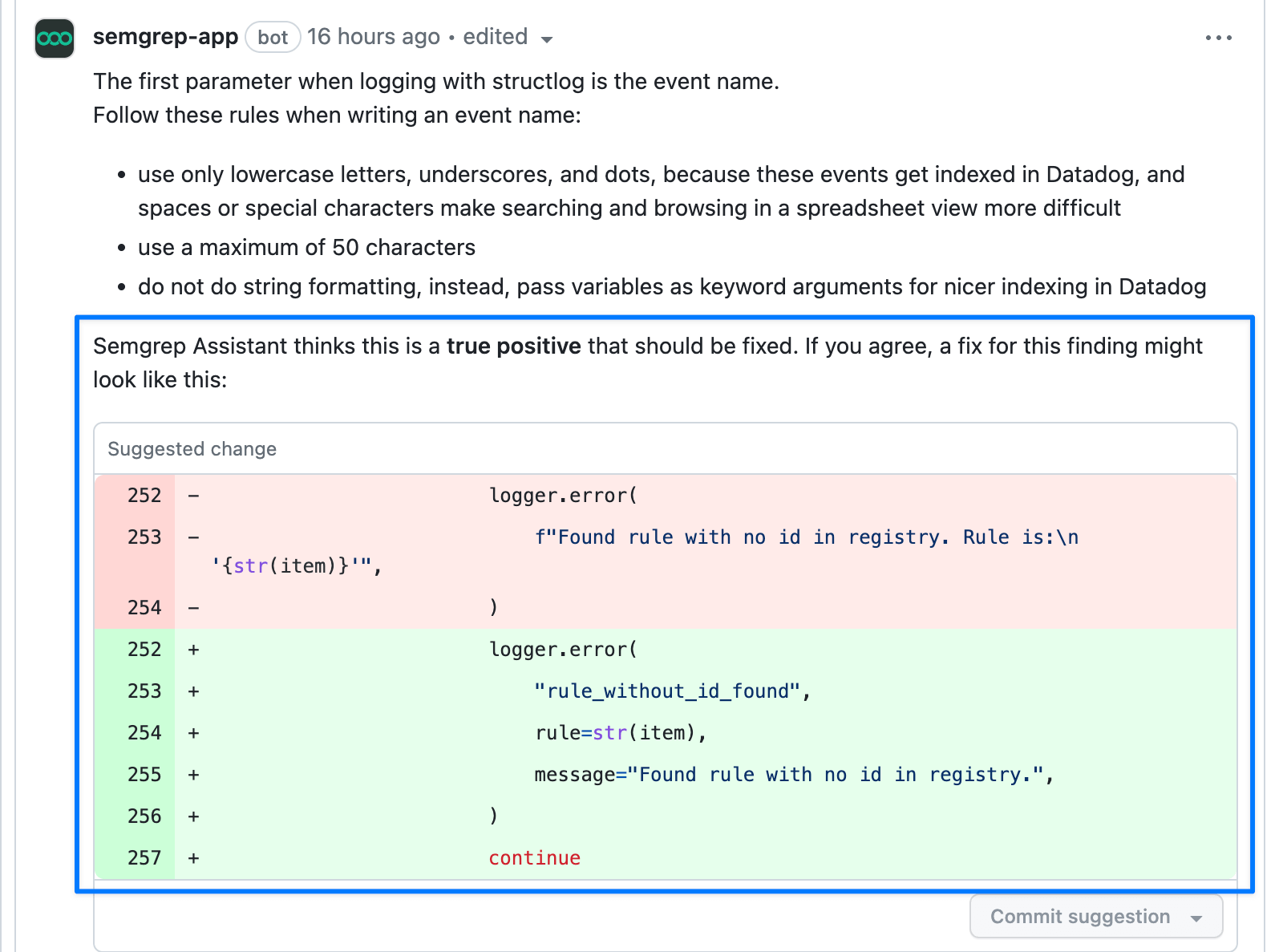 Our hypothesis is that showing an attempted fix – even if wrong – helps junior engineers grasp the problem the rule message attempts to describe. Show, don't tell.
Our hypothesis is that showing an attempted fix – even if wrong – helps junior engineers grasp the problem the rule message attempts to describe. Show, don't tell.
How do we expect this to change things
Putting on our wild, unsubstantiated prediction hats, we can start daydreaming about a possible world for SAST tools in 2028. Assuming that GPT-N demonstrates an ability to make the correct change to code 95% of the time, what is Semgrep for? Well, even in 2023, security teams require a certain level of visibility into the scanning process. Many teams choose Semgrep today over black box systems, because Semgrep rule syntax makes it easy to predict what would and would not match. Without substantial AI interpretability research (and boy are we behind on that!) it's difficult to imagine a mid+ maturity security team trusting an end-to-end AI system to review code.
A possible future is that Semgrep Assistant plugs into the system on both ends: an AI rule writer on one, and an AI code reviewer on the other.
The AI rule writer determines the code patterns (in the format of Semgrep rules) which define which code snippets determine attention to what kind of worry.
The Semgrep Registry & Engine remain the pieces that find code snippets of interest. This is the crucial bit that must happen on the surface, so that humans can understand and manually reproduce how code review actually happens.
The AI code reviewer then investigates each finding and identifies the snippets of interest that require the most immediate attention.
A matter-of-fact description of the Semgrep Registry today is "thousands of community-maintained Semgrep rules." A more ambitious mental model we've sometimes used for it is "an encyclopedia of humanity's coding knowledge." If the above vision comes true, this is about to shift to "a library of GPT prompts for useful code review and code edits."
And to make a short-term prediction, thanks to the great performance on coding standards rules, we expect that devs using Semgrep's AI features will write a lot more custom rules. The productivity gain from just having these things fixed for you without needing a discussion is similar to a code auto-formatter, like go fmt or black.
Try it yourself
If this got you excited, the good news is the private beta of both these features is open for signups as of today. While in beta, we're still working on getting more useful autofix suggestions. Make sure to use the same email address you use on your Semgrep Code account, as we will prioritize accounts with multiple actively scanned projects and custom rules.
(These AI features are also the first time we've ever requested access to a user's code. If you join the private beta, we will request GitHub code access, and snippets of your code will be forwarded to OpenAI. We will, however, not store any of your code, and OpenAI will not use your code snippets[4] for training their models).
[1]: Xie, J., Chu, B., Lipford, H.R. and Melton, J.T., 2011, December. ASIDE: IDE support for web application security. In Proceedings of the 27th Annual Computer Security Applications Conference (pp. 67-276).
[2]: Ye, T., Zhang, L., Wang, L. and Li, X., 2016, April. An empirical study on detecting and fixing buffer overflow bugs. In 2016 IEEE International Conference on Software Testing, Verification and Validation (ICST) (pp. 91-101). IEEE. Vancouver
[3]: Higuera, Juan R. Bermejo, et al. “Benchmarking approach to compare web applications static analysis tools detecting OWASP top ten security vulnerabilities.” Computers, Materials and Continua 64 (2020): 3. APA


.jpg)
